SANA‑WM is a 2.6 billion‑parameter camera‑controlled world model that synthesizes 60 seconds of 720p video from a single initial image and an action trajectory, offering metric‑scale 6‑DoF camera control. The release focuses on lowering inference‑side compute so minute‑scale, camera‑conditioned rollouts can run on a single GPU while preserving options for high‑quality offline synthesis and sequential rollouts for embodied agents.
The authors publish code and model files in the NVlabs/Sana GitHub repository, building the release on the prior SANA‑Video codebase. SANA‑WM is implemented as a Diffusion Transformer (DiT) trained natively for one‑minute 720p generation using 64 H100 GPUs, so reproducing its training still requires large H100 clusters even though inference can be far cheaper.
For deployment, SANA‑WM provides three single‑GPU inference variants: a bidirectional generator for higher‑quality offline synthesis, a chunk‑causal autoregressive generator for sequential rollouts, and a few‑step distilled autoregressive generator optimized for low latency. With NVFP4 quantization, the distilled variant denoises a 60‑second 720p clip in 34 seconds on a single RTX 5090, demonstrating a practical single‑GPU runtime path.
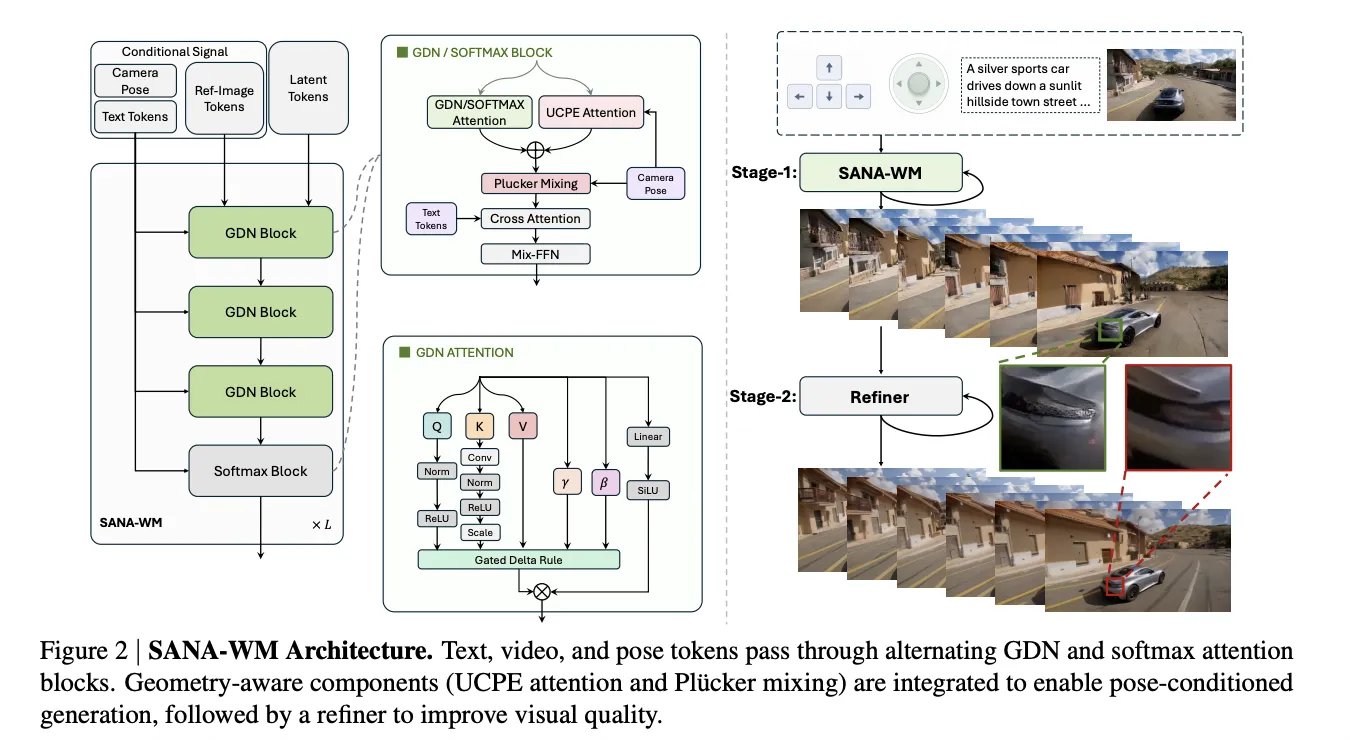
To scale to long sequences without exploding memory or compute, the backbone replaces most attention blocks with a frame‑wise Gated DeltaNet (GDN). This recurrent GDN processes one latent frame per step and uses a decay gate γ plus a delta‑rule correction so the recurrent state stays a constant D×D size regardless of video length. The authors also introduce an algebraic key‑scaling of 1/√(D·S) to bound the transition spectral norm and prevent the NaN divergence seen with other normalization schemes.
The final transformer backbone is a hybrid: 20 total blocks interleave 15 frame‑wise GDN blocks with five softmax attention layers placed at layers 3, 7, 11, 15 and 19. Those occasional softmax attention blocks provide exact long‑range recall where recurrence alone underperforms, and the hybrid design specifically mitigates drift observed in prior SANA‑Video linear‑attention architectures that accumulated past frames without decay.
Camera control is implemented with two complementary branches operating at different temporal rates. A coarse branch uses UCPE (Unified Camera Positional Encoding) at the latent‑frame rate to inject a ray‑local camera basis into attention heads and capture global trajectory structure. A fine branch computes pixel‑wise Plücker raymaps from the eight raw frames summarized in each latent token, packs them into a 48‑channel tensor, and injects that embedding after self‑attention via a zero‑initialized projection to restore intra‑stride motion.
Ablations on OmniWorld show both camera branches are required to match full performance. For practitioners, the release and accompanying paper (available on arXiv) present concrete tradeoffs between quality, latency and hardware cost: SANA‑WM lowers inference compute for minute‑scale, camera‑conditioned rollouts and supports faster single‑GPU deployment via the distilled path, while centralized training remains compute‑intensive.
Sources
Replies (0)
No replies in this topic yet.