Stability AI today published small and medium weights for Stable Audio 3 (SA3) and a companion technical paper, making long-form stereo 44.1 kHz music and sound generation and editable workflows available to developers on consumer hardware. The release opens up generation, duration control and inpainting — style edits for practical, locally runnable audio models; the largest SA3 model is withheld under an enterprise license.
SA3 ships in three diffusion — transformer scales. The small music and SFX variants use a 459M-parameter diffusion transformer and support outputs up to two minutes. The medium model runs a 1.4B-parameter transformer and supports music and SFX up to 6 minutes 20 seconds. The large model is a 2.7B-parameter transformer reserved for enterprise customers.
Each diffusion scale is paired with SAME autoencoder variants: SAME-S (108M) for the small model, and SAME-L (852M) for both medium and large. All models generate stereo audio at 44.1 kHz and target practical inference: the small model can run on a MacBook Pro M4 CPU, while the medium model fits on consumer GPUs with roughly 8 GB of VRAM. Open small and medium weights are hosted on Hugging Face; access to the large model requires an enterprise license.
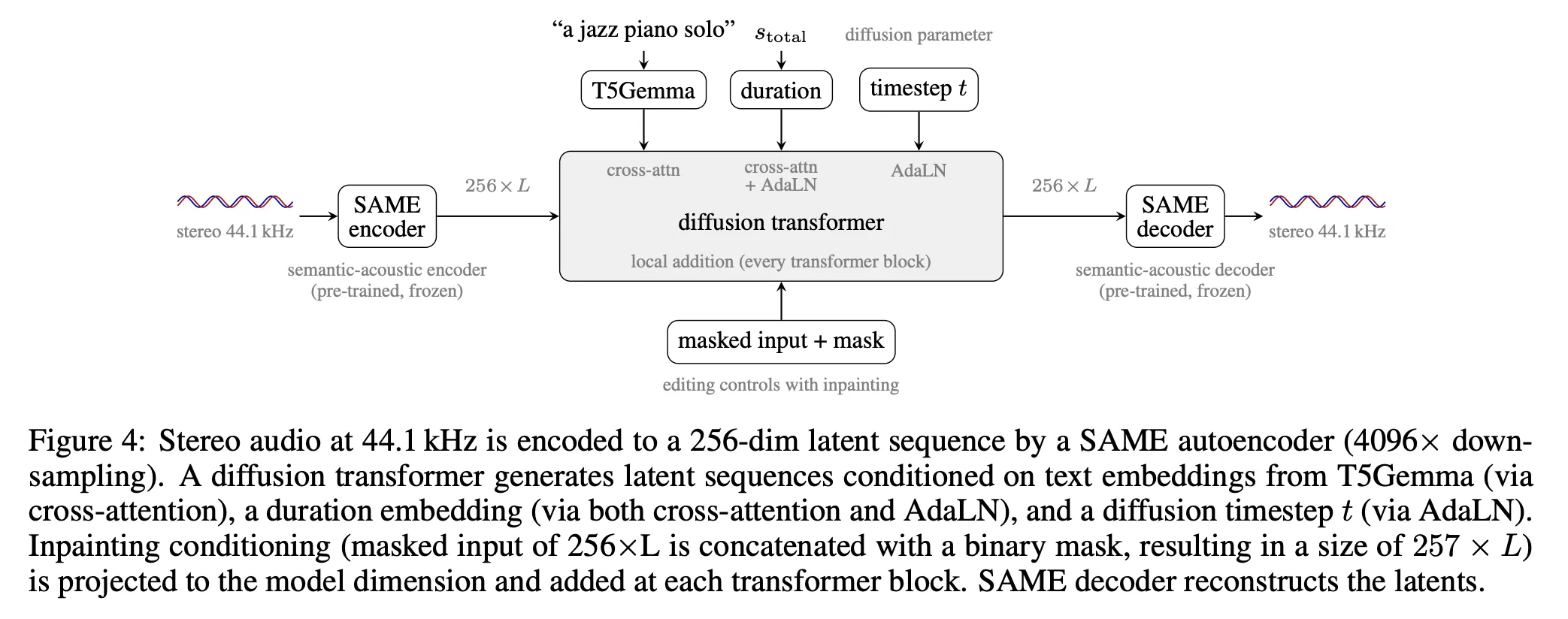
SAME (Semantically — Aligned Music autoEncoder) compresses stereo 44.1 kHz audio by a 4,096× ratio to produce a 256 — dimensional latent sequence at about 10.76 Hz for a 44.1 kHz input. SAME implements a two-step pipeline: a patching stage performs 256× downsampling using 256 — sample non-overlapping stereo patches, and a Transformer Resampling Block (TRB) applies an additional learned 16× downsampling to produce the latent sequence.
The diffusion transformer generates sequences of SAME latents conditioned along three pathways. Text prompts are encoded by a frozen T5Gemma into 256 embeddings of dimension 768. Duration is encoded as Fourier features and injected via Adaptive Layer Normalization plus cross — attention. Inpainting masks are projected through a two-layer MLP and added into each transformer block. Medium and large models add a differential — attention mechanism and prepend 64 learnable memory embeddings to the transformer.
Training follows a three — stage pipeline — flow matching, distillation warmup, and adversarial post-training—with the SAME autoencoder frozen during diffusion training. SAME itself is trained with five loss terms: spectral reconstruction, adversarial, diffusion alignment, semantic regression (predicting chroma and interaural level difference), and contrastive latent alignment. On the BBC Sound Effects benchmark at 5 seconds, SA3 medium reported an FAD of 0.369, lower than every open-weight baseline evaluated in the paper.
For developers and builders, SA3’s high compression and multi — path conditioning are intended to enable long-form generation and editable audio workflows on modest hardware, while reserving the higher — capacity large model for production and enterprise deployments. The published paper and open small and medium weights on Hugging Face let teams experiment with inpainting, text conditioning and duration control locally before moving to the enterprise — tier model if needed.
Sources
Replies (0)
No replies in this topic yet.