StepFun, a Shanghai — based AI lab, released StepAudio 2.5 Realtime in May 2026 — an end-to-end real-time speech large language model with fully customizable persona capabilities.
StepFun published technical documentation, benchmarks and an interactive demo for StepAudio 2.5 Realtime in May 2026, unveiling an end-to-end real-time speech LLM that lets callers interact with configurable personas. The release provides concrete access instructions and evaluation results so builders can reproduce the system and test persona — driven voice agents in real time. The model is accessible over a WebSocket API at wss://api.stepfun.com/v1/realtime and uses the model string step-2.5 — realtime. It supports Chinese and English, carries forward TTS capabilities from StepAudio 2.5, and is presented as a single — stage audio pipeline: raw audio in and synthesized audio out without separate ASR, reasoning, and synthesis modules.
StepFun credits three technical pillars for the system. First, a million — scale persona augmentation pipeline expanded more than 10,000 natively authored personas into a persona feature matrix using algorithmic expansion and millions of conversational samples. Second, roleplay — specific RLHF was applied to reduce out-of-character drift. Third, a reinforcement — learning–based fusion of speech understanding and generation enables what the authors call “global scene — level tonal setting” and “intra — sentence detail sculpting.
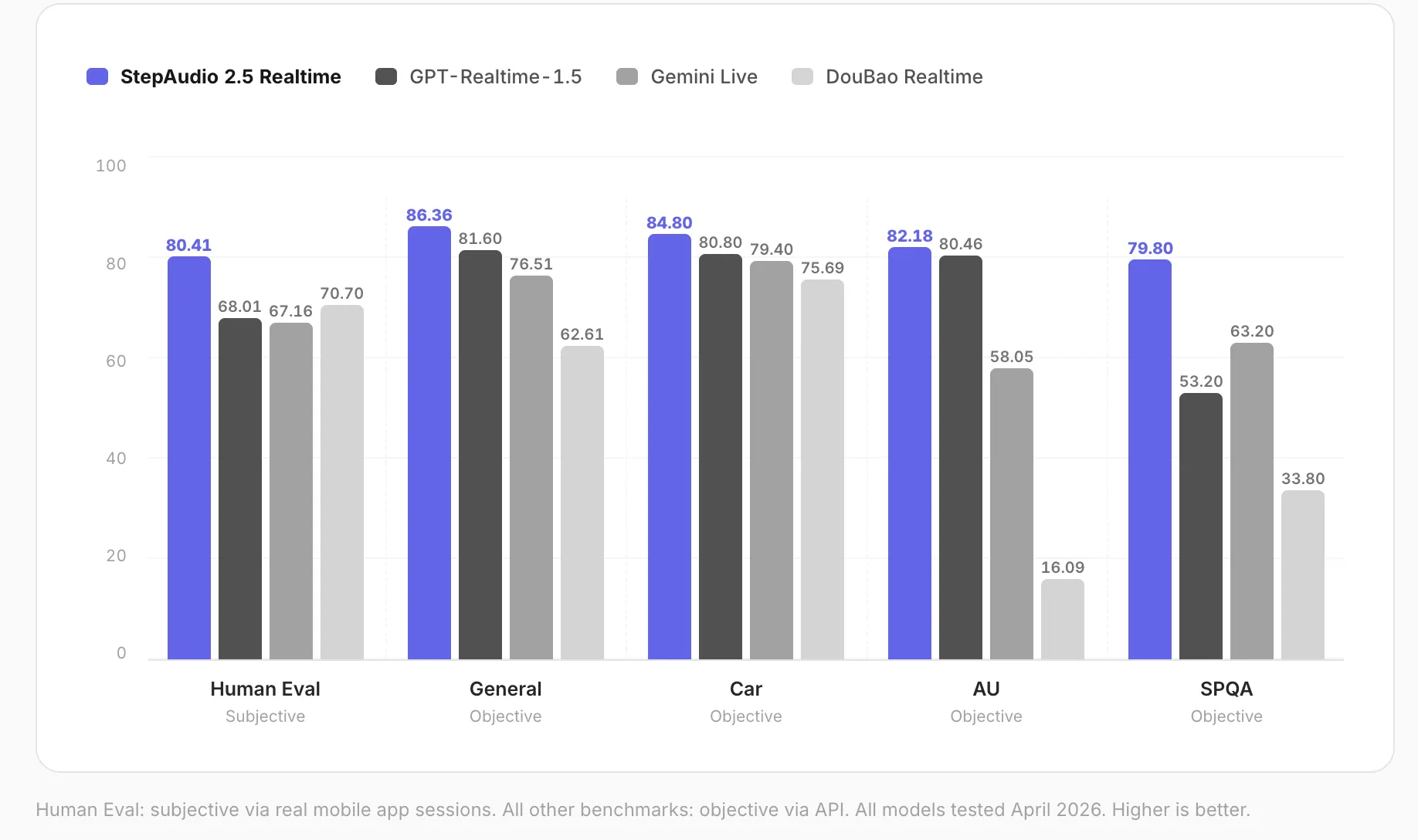
In April 2026 the team ran a suite of subjective and objective benchmarks and reports that StepAudio 2.5 Realtime ranked first across five tested dimensions against leading real-time voice models. Reported scores are: human evaluation (subjective) 80.41; general dialogue (objective) 86.36; automotive scenario (objective) 84.80; spoken QA (11 audio tasks) 79.80; and paralinguistic comprehension (objective) 82.18.
StepFun highlights paralinguistic comprehension as a core differentiator: the model analyzes non-verbal acoustic cues-tone, speaking rate, pauses, sighs and laughter — to infer mood and intent. The team gives examples such as identifying fatigue from low tone or frustration from rapid speech rate; the paralinguistic metric (82.18) is said to measure perception of vocal speed, emotion, age and related acoustic features.
For builders the release bundles practical artifacts: the WebSocket API endpoint and model string for real-time integration, an online demo and a model card. StepFun positions the million — scale persona augmentation together with roleplay — focused RLHF as a way to improve persona stability in long conversations, and the unified audio pipeline as a simpler integration path compared with multi — stage stacks that separate ASR, reasoning and TTS.
Sources
Replies (0)
No replies in this topic yet.