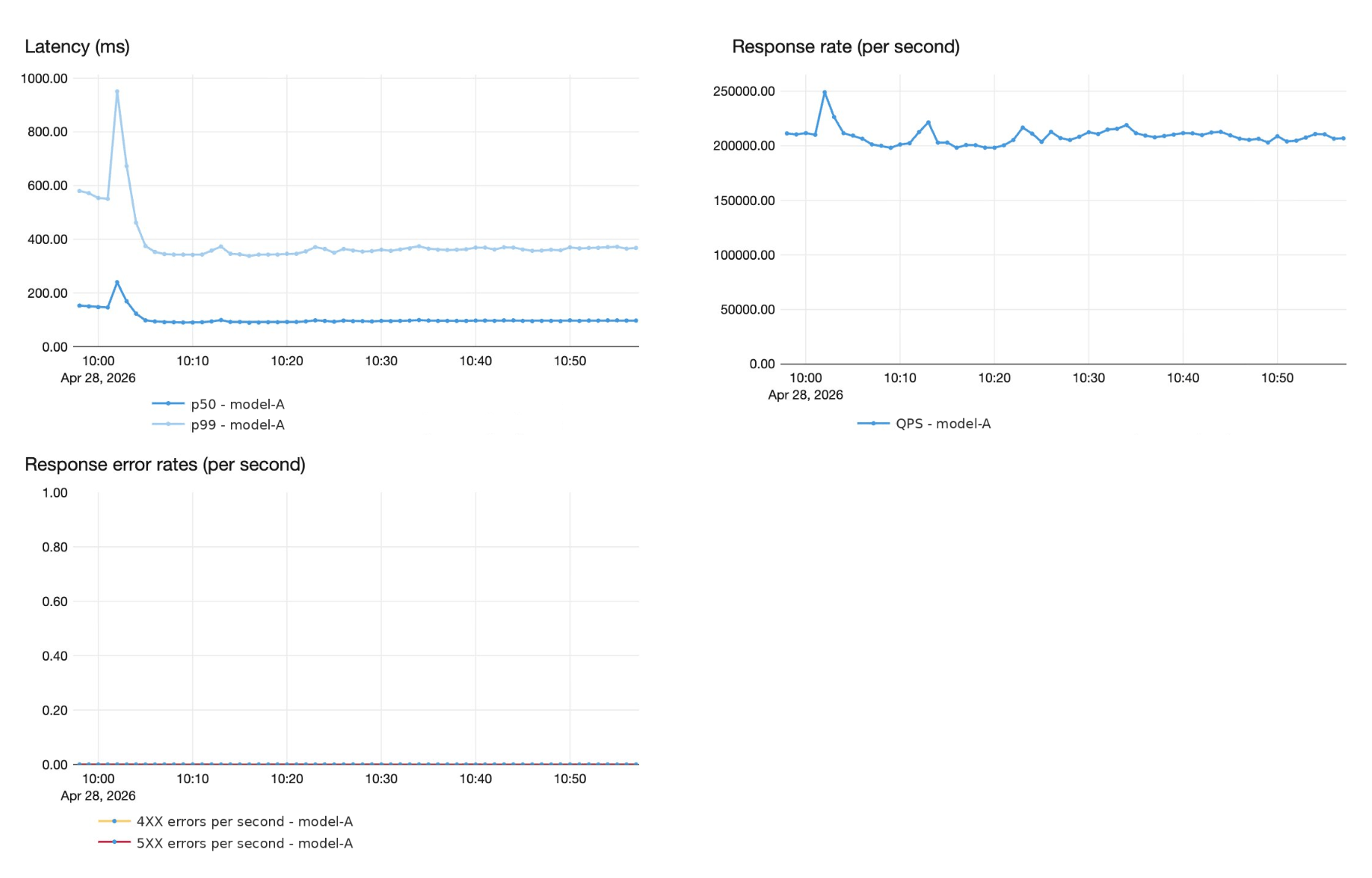
Superhuman migrated its high‑volume spelling and grammar correction model from a DIY vLLM stack to a managed FMAPI Provisioned Throughput deployment, unlocking >200,000 QPS, sub‑second P99 latency, and freeing its ML team from months of manual tuning.
Superhuman shifted its real‑time grammar and spelling correction model from an in‑house vLLM stack to a managed FMAPI Provisioned Throughput deployment, achieving peak traffic above 200,000 queries per second and end‑to‑end P99 latency under one second. The migration matters because it preserves low latency and strict availability while offloading operational burden, enabling the small ML infrastructure team to refocus on model quality and product work for a user base that spans millions daily.
The move was prompted by growing operational strain: the DIY vLLM stack demanded months of manual tuning and significant capacity planning, which distracted engineers from improving the model itself and integrating product features. Superhuman historically used a separate analytics platform for batch workloads, but the real‑time inference workload required stronger SLAs for latency and availability and a different operational model.
On the implementation side, Superhuman replaced the DIY stack with FMAPI Provisioned Throughput to serve a custom LLM for grammatical error correction. Engineering changes included FP8 quantization to reduce serving costs, removing CPU‑side overhead, and tuning attention kernels for the Hopper architecture. Those optimizations produced roughly a 60% per‑GPU throughput increase — from about 750 QPS to roughly 1,200 QPS per H100 pod-without measurable quality regressions on Superhuman’s internal evaluation harnesses.
Running on the managed platform, the correction model now sustains peak traffic above 200,000 QPS while meeting strict reliability targets (four nines) and keeping P99 latency below one second. Offloading serving and autoscaling responsibilities to a managed service eliminated months of manual performance tuning and freed the ML team to prioritize model improvements and product innovation rather than operational chores.
The managed FMAPI deployment was hardened for production at scale: it implements production‑grade load balancing (including power‑of‑two strategies to absorb strong diurnal ramps), autoscaling, fast container startup, and pre‑production ramp stress testing to validate P99 availability and latency before traffic reaches production. Combined platform and application optimizations enable reliable scaling beyond 250 GPUs.
For builders, the case underscores concrete tradeoffs and practical wins: measured per‑pod throughput gains (≈750 → ≈1,200 QPS per H100 pod); FP8 quantization to cut costs while preserving model quality; and infrastructure‑level fixes that removed CPU‑side bottlenecks. The report stresses that meeting single‑pod latency targets is necessary but insufficient for 200K+ QPS; robust load balancing, autoscaling, and pre‑production stress testing were essential to satisfy real‑time SLOs.
Sources
Replies (0)
No replies in this topic yet.