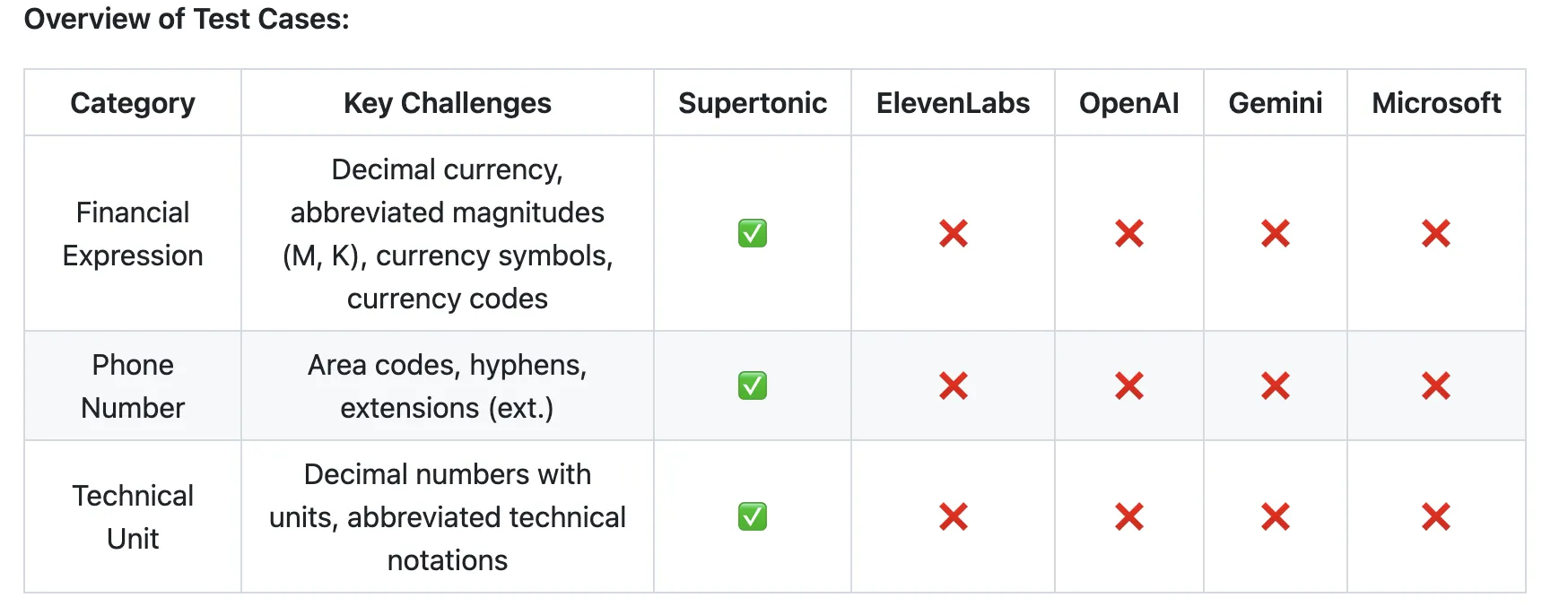
Supertone has released Supertonic 3, the third generation of its on‑device, ONNX‑based text‑to‑speech (TTS) system, touting broader language support and greater reading stability. The company describes the release as “Lightning Fast, On‑Device, Multilingual and Accurate TTS.” The update preserves v2‑compatible public ONNX assets and keeps the inference contract unchanged, so existing integrations should remain compatible. Compared with Supertonic 2, the new version reduces repeat and skip failures in reading and improves speaker similarity within the shared language set. Supertonic 2 supported five languages — English, Korean, Spanish, Portuguese and French — and Supertonic 3 expands that baseline to cover a much wider set of languages.
Supertonic 3 adds Japanese, Arabic, Bulgarian, Czech, Danish, German, Greek, Estonian, Finnish, Croatian, Hungarian, Indonesian, Italian, Lithuanian, Latvian, Dutch, Polish, Romanian, Russian, Slovak, Slovenian, Swedish, Turkish, Ukrainian and Vietnamese, bringing the total to 31 ISO language codes. The release also includes a special “na” fallback for text whose language is unknown or is outside the supported set. The model grew modestly to accommodate the added languages while maintaining on‑device suitability.
The public ONNX assets for Supertonic 3 total about 99 million parameters across the distributed models, keeping the system far smaller than many open TTS models in the 0.7 billion to 2 billion parameter range. That smaller footprint is positioned as a practical advantage for download size, startup time and on‑device inference performance. Supertone reports the total disk footprint of the public ONNX assets is 404 MB. Alongside the model update, Supertone has launched Voice Builder, a tool that lets developers create custom, edge‑native TTS models from their own voice recordings. Voice Builder is designed to produce models suitable for on‑device deployment, complementing Supertonic 3’s focus on compact, local inference.
One new capability in Supertonic 3 is support for expressive tags, which allow developers to add basic expressive cues to synthesized speech. The addition of expression tags aims to improve the naturalness and versatility of on‑device voices without increasing the size class of the public assets.
Sources
Replies (0)
No replies in this topic yet.