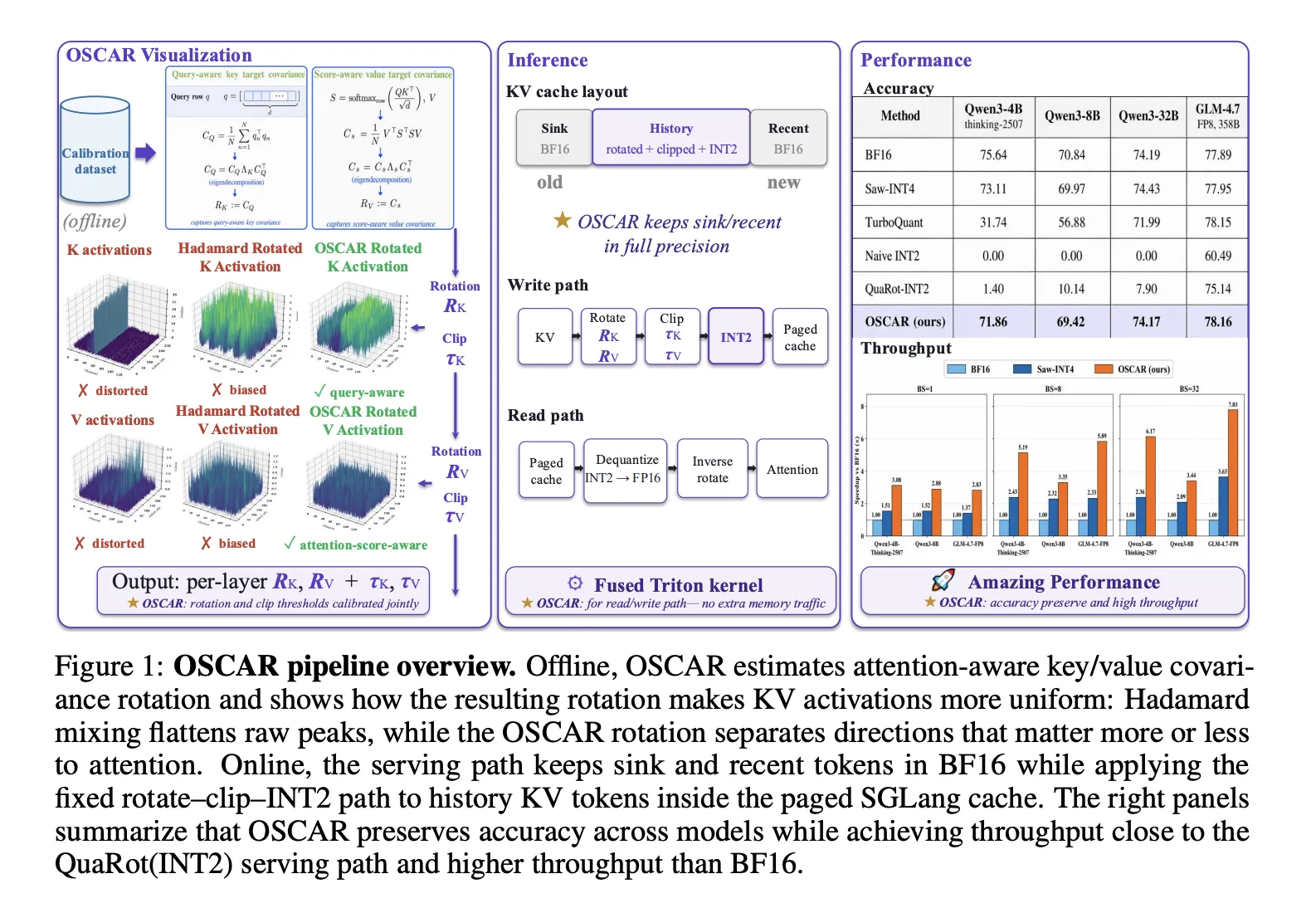
Together AI has published OSCAR (Offline Spectral Covariance — Aware Rotation), an INT2 KV-cache quantization method plus code and paper that makes 2 — bit KV caching practical for long-context autoregressive decoding workloads where KV memory dominates GPU usage. The team demonstrates an effective 2.28 bits per KV element, provides benchmarks showing large memory and speed gains, and outlines a path to integrate the method into production serving stacks.
OSCAR’s core technical change is attention — aware rotation: rotations for keys and values are estimated offline from attention statistics instead of from raw activations. For keys OSCAR uses the empirical query covariance CQ = (1/N) Σ qn⊤qn and takes its eigenvectors UQ; for values it uses a score — weighted value covariance CS = (1/N) V⊤S⊤SV and eigenvectors US. The final rotations are composed as RK = UQ·HHad·Pbr and RV = US·HHad·Pbr, combining the eigenbases with a Walsh — Hadamard transform (HHad) and a permuted bit-reversal (Pbr).
The authors contrast OSCAR with prior low-bit approaches that relied on data-oblivious Hadamard transforms or required custom serving layouts. At INT2 precision, channel — wise outliers and the query — weighted sensitivity of attention logits make uniform rotations inadequate; previous INT2 attempts either collapsed accuracy or were incompatible with paged KV-cache systems used in production serving.
Measured effects for builders are concrete. OSCAR reduces KV memory roughly 8x and yields up to 3x faster decoding at 100K token context lengths. At its effective 2.28 bits per KV element OSCAR narrows the BF16 accuracy gap to 3.78 points on Qwen3 — 4B-Thinking-2507 and to 1.42 points on Qwen3 — 8B. Those improvements translate into higher batch sizes, lower memory traffic, and more feasible long-context service levels on an unchanged GPU fleet.
The release includes a production integration: OSCAR was implemented as an INT2 KV-cache mode in SGLang’s serving stack with full compatibility with paged attention. The system uses a mixed — precision KV layout with three regions per request; notably the most recent sink tokens region (S0 = 64 tokens) remains in BF16 to preserve recent context fidelity while older tokens are stored in quantized form.
The paper supplies theoretical support and a practical calibration workflow. It presents a theorem proving UQ/US optimality under a frozen — error surrogate with diagonal residuals and prescribes offline estimation of rotations from representative query/value samples. That offline calibration, combined with per-group bit-reversal and HHad equalization, addresses INT2 failure modes and makes 2 — bit KV caching a deployable option for long-context LLM serving.
Sources
Replies (0)
No replies in this topic yet.