Tomofun, maker of the Furbo Pet Camera, has shifted parts of its inference fleet to Amazon EC2 Inf2 instances powered by AWS Inferentia2 chips so BLIP‑based vision — language models can run at lower operational cost. The company preserved its existing GPU path and did not change upstream APIs or downstream alert logic, ensuring live pet‑behavior detection — barking, running and unusual activity — continues to operate as before.
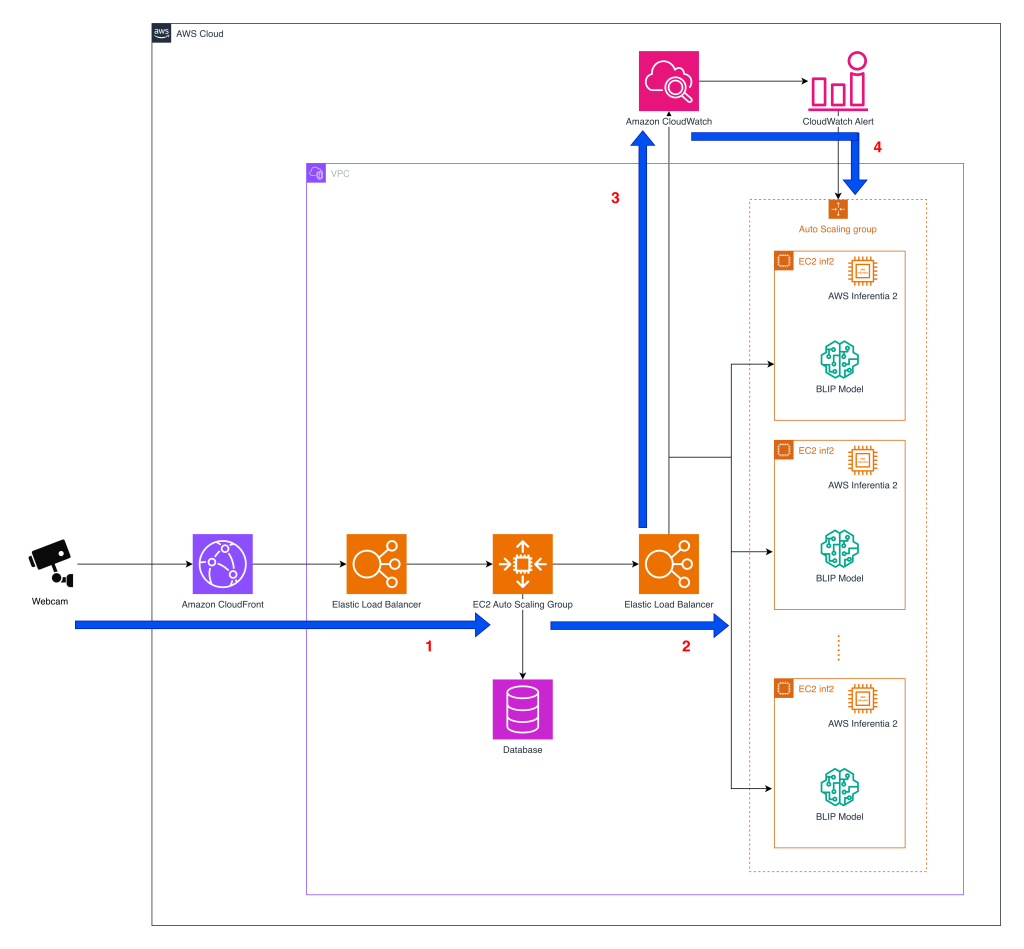
The deployed architecture uses a two‑layer Auto Scaling design. An initial API layer ingests camera frames through CloudFront and an Elastic Load Balancer and forwards images to a second Auto Scaling group dedicated to model inference. Containers in the inference layer host BLIP components compiled with the Neuron SDK and can run on Inf2 instances; the API is capable of routing requests to either GPU or Inferentia2 containers in real time.
Tomofun’s previous setup relied on GPU‑based EC2 instances that delivered high throughput but proved expensive for always‑on, real‑time inference across a large device base. The engineering team balanced two constraints: sustain near‑continuous monitoring across hundreds of thousands of devices while preserving model fidelity and throughput, and avoid rewriting substantial portions of BLIP code that had been optimized in PyTorch.
Operational observability and autoscaling were central to the rollout. Amazon CloudWatch collects latency, throughput and error‑rate metrics across the inference fleet; those signals feed Auto Scaling decisions. The company drives scaling by request‑count metrics tied to throughput benchmarks derived from stress testing, so capacity follows image request volume rather than fixed schedules. For builders, the practical takeaway is that PyTorch‑optimized BLIP components can be compiled with the Neuron SDK and deployed in containers on Inf2 instances without altering client‑facing APIs. That preserves the existing Furbo alerting flow while allowing teams to shift traffic between GPU and Inferentia2 backends according to load or cost targets.
combine chip‑optimized inference hardware, containerized VLM components, request‑driven autoscaling and CloudWatch observability to maintain availability and throughput while reducing operational inference cost at scale.
Sources
Replies (0)
No replies in this topic yet.