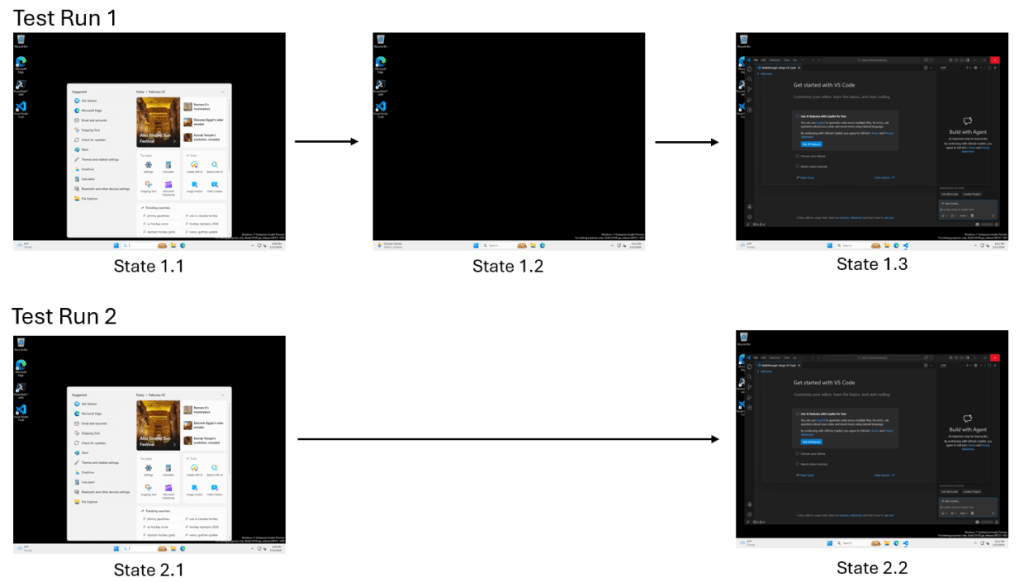
An engineering blog proposes a validation approach for Copilot Coding Agent (Agent Mode) that accepts multiple valid execution paths and focuses on outcome validation rather than rigid step-by-step matching.
Modern software testing assumes correct behavior is repeatable; that assumption breaks down for autonomous agents such as Copilot Coding Agent (Agent Mode). When agents move from inline suggestions to interacting with real environments — UIs, browsers, IDEs and containerized hosts — valid executions can follow multiple paths and exhibit timing and rendering variability that traditional tests were not designed to tolerate.
The post describes a practical failure seen in Actions pipelines: an agent adapts to a transient loading delay on a hosted runner and completes its task, yet the CI run is marked failed because a recorded script or timing assertion no longer matches the actual steps. To address this, the author proposes a “Trust Layer” and advocates using dominatory analysis — validating outcomes and acceptable behaviors rather than enforcing a single, rigid sequence of steps — so checks remain explainable and lightweight enough for CI.
Common testing paradigms struggle with agentic behavior for predictable reasons. Assertion‑based tests demand labor‑intensive, path‑specific checks; record‑and‑replay tooling is brittle and highly sensitive to environmental noise; and visual regression comparisons can detect surface differences while missing the semantics of multi‑path success. Applied to agents using Computer Use in containerized cloud environments, those limitations produce brittleness that signals regressions even when the task has completed correctly.
The post identifies three recurring pain points that create a trust gap in agent‑driven testing. First, false negatives occur when a task genuinely succeeds but the runner rejects the result because execution steps differ. Second, fragile infrastructure failures arise from timing or rendering noise that breaks narrow assertions. Third, a compliance trap emerges when correct outcomes nonetheless trigger regressions because agent behavior diverges from an expected script. Each of these can halt production pipelines and erode confidence in automation.
For builders, the recommended shift is explicit: move from verifying exact execution traces to asserting essential end‑state properties and tolerances. Practically, that means instrumenting CI to check what must have happened for success (for example, data persisted, UI state achieved, or side effects observed), collecting and encoding alternative valid paths, and separating incidental noise (loading delays, transient rendering differences) from critical failures such as lost data or incomplete transactions.
The proposed model is designed to be explainable and lightweight so it can be integrated into real‑world CI pipelines and scale with agent capabilities. By prioritizing outcome validation and applying dominatory analysis, teams can reduce false negatives, make tests less brittle, and increase trust in agentic workflows that interact with complex, non‑deterministic environments.
Sources
Replies (0)
No replies in this topic yet.