Uber has rolled out an updated recommendation stack for the Uber Eats Home Feed designed to make restaurant discovery more responsive to active browsing and immediate user intent. The deployment targets homepage and discovery surfaces with the stated goal of surfacing more relevant restaurants within a single session while improving ranking efficiency across candidate sets; the company tightened feature freshness from 24 hours to seconds to support that responsiveness.
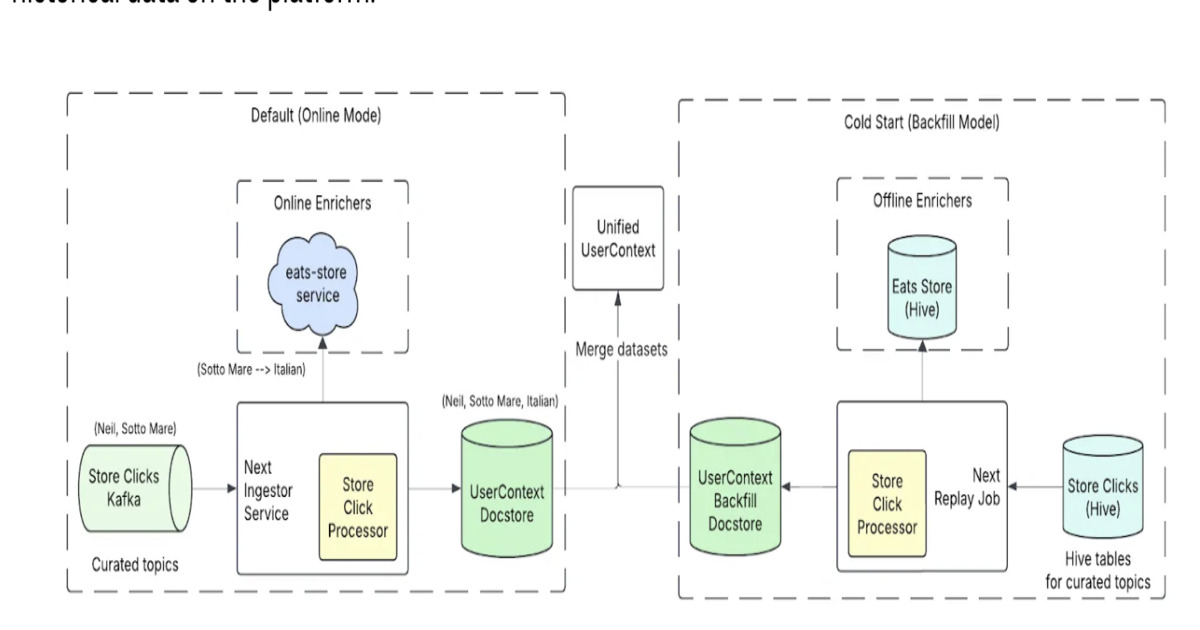
The new architecture replaces earlier batch — oriented feature pipelines with a near-real-time signal processing layer that continuously ingests clicks, searches and order history so user representations remain current during a session. Rather than waiting for daily batches, the pipeline streams these interaction signals into feature computation, enabling the model to react to what a user is doing right now rather than relying on stale summaries.
Algorithmically, Uber moved away from hand-crafted statistical features toward transformer — based sequence modeling and a Generative Recommender — style model to represent user behavior. That shift treats recent actions as ordered sequences, which the company says helps capture short — term intent and contextual patterns that matter for immediate restaurant recommendations. The combined approach is intended to use richer, learned features in place of manually engineered signals.
A key ranking change is the adoption of listwise evaluation: multiple restaurant candidates are scored together in a single inference step instead of being scored independently (pointwise). Uber reports that listwise ranking makes it possible to directly compare candidates in the same context, improving both computational efficiency and ranking quality versus pointwise scoring. To reduce feature drift and align offline training with online serving, Uber replays historical user sessions to generate training examples and applies the same feature — extraction logic in training and production. This training — serving parity is intended to make models trained on replayed sessions behave more like models in live inference and to narrow discrepancies between offline and online performance.
On the infrastructure side, Uber separates feature preprocessing from model inference to meet low-latency constraints on consumer — facing surfaces: upstream services handle feature computation and aggregation while the serving layer focuses on ranking decisions. Product and engineering leads, including Brinda Panchal and Yicheng Chen, framed the effort as a balance between real-time user intent, a diverse merchant ecosystem and complex ranking objectives to create a smoother discovery experience.
Sources
Replies (0)
No replies in this topic yet.