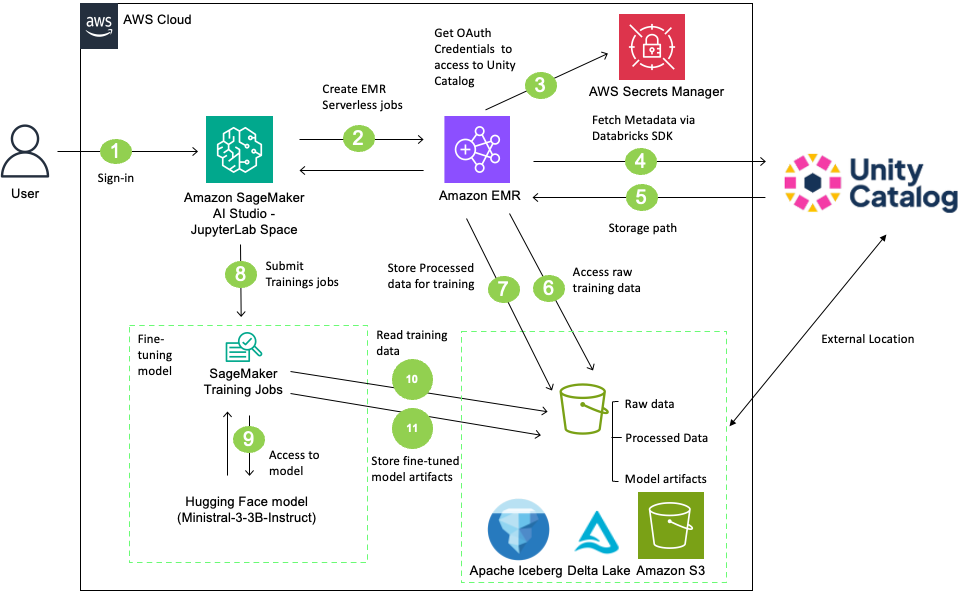
A new walkthrough details how teams can fine‑tune large language models while keeping Databricks Unity Catalog as the single source of metadata and access control. It demonstrates an integration pattern that prevents training jobs from bypassing catalog authorization — addressing visibility and compliance gaps that can arise when managed ML services access S3 data directly. This matters for production pipelines and regulated environments where consistent policy enforcement and audit trails are required.
The workflow reads training data from a Unity Catalog‑managed table, preprocesses it with Amazon EMR Serverless running Apache Spark, and launches Amazon SageMaker AI Training jobs to fine‑tune the Ministral — 3-3B-Instruct model. Preprocessing is initiated from SageMaker AI Studio’s JupyterLab space; EMR Serverless accesses the managed S3 data via Unity Catalog Open REST APIs using OAuth credentials. The solution references Hugging Face for pre‑trained models and uses AWS Secrets Manager for credential management.
The walkthrough highlights the governance risks of not following this pattern: if SageMaker AI Training jobs circumvent Unity Catalog authorization, organizations can face inconsistent policy enforcement, missing audit trails, and compliance exposure. Those risks are particularly acute for regulated industries and production workloads, where lineage, permission checks, and centralized logging are critical.
By integrating Unity Catalog, EMR Serverless, and SageMaker AI, the pattern preserves centralized governance while allowing teams to continue using existing managed services. It supports tracking lineage from the source table through preprocessing to the trained artifact, registering trained models back into the catalog, and retaining credential and audit controls — reducing compliance and visibility risks in ML pipelines.
Sources
Replies (0)
No replies in this topic yet.