Zyphra released ZAYA1-8B-Diffusion-Preview, a technical preview that converts an autoregressive mixture‑of‑experts (MoE) language model into a discrete diffusion‑style model. The preview shows the conversion can preserve evaluation quality while enabling block decoding that reduces per‑request memory traffic, a change the company says can materially improve inference throughput on memory‑bound hardware. This path could matter most to builders seeking lower inference memory pressure without retraining large pretraining stacks.
The conversion began from the ZAYA1-8B-base checkpoint and used a TiDAR‑based recipe with additional mid‑training. Zyphra reports performing 600 billion tokens of diffusion conversion at a 32k context length, then 500 billion tokens of native context extension to 128k, followed by a diffusion supervised fine‑tuning (SFT) phase. At inference the converted model drafts blocks of 16 tokens and applies a single‑step mask‑to‑token transform for each token in the block instead of performing iterative denoising.
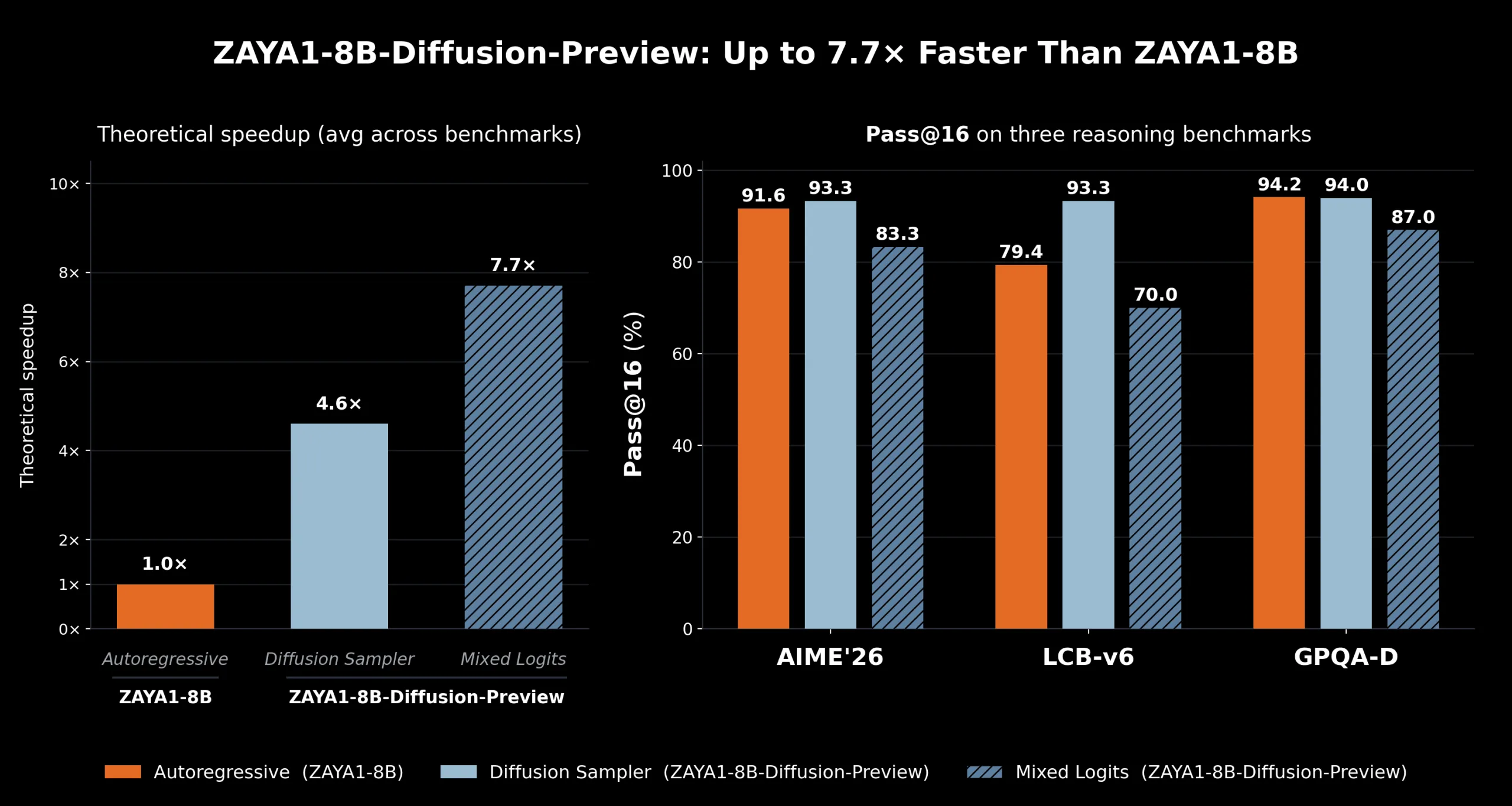
Zyphra frames a primary bottleneck in autoregressive decoding as KV‑cache reads: because each request has a different token history, those reads create per‑request memory traffic that leaves many GPUs memory‑bandwidth‑bound. By producing multiple tokens in a shared block, the diffusion approach allows the block to share a single KV state and increases compute work per memory byte, which better matches modern accelerators where FLOPs have scaled faster than memory bandwidth.
On AMD hardware in strongly memory‑bound regimes, Zyphra reports up to 7.7× inference speedup relative to the autoregressive baseline. They also report that evaluation shows no systematic degradation versus the autoregressive checkpoint and even some benchmark gains, with the team citing improvements on LCB‑v6. Zyphra argues that conversion can be preferable to training diffusion models from scratch because the objective is to realize inference‑time benefits while reusing pretraining investments.
A notable sampler design choice is that the same model serves as both speculator and verifier in a single forward pass, adopting an acceptance criterion from speculative decoding. That design removes the overhead of running two separate models as in approaches like EAGLE or dFlash. Zyphra describes two samplers with distinct speed trade‑offs and notes that in highly memory‑bound settings many accepted tokens are effectively “free” because the GPU is already loaded.
For builders, the preview offers a concrete route to reduce inference memory traffic without redoing pretraining: conversion, context‑extension and SFT can retain quality while enabling block decoding patterns that improve GPU utilization, particularly on AMD accelerators. Zyphra emphasizes this is early research and a preview rather than a final product; teams should validate throughput, acceptance rates, and benchmark performance on their own workloads before production adoption.
Sources
Replies (0)
No replies in this topic yet.