Zyphra has released ZAYA1-8B, an Apache 2.0 Mixture — of-Experts model (8.4B total, 760M active) with MoE++ optimizations, trained on 1,024 AMD MI300x nodes and scoring 89.6 on HMMT'25.
Zyphra has released ZAYA1-8B, an 8.4 — billion-parameter Mixture of Experts language model published under an Apache 2.0 license and made available on Hugging Face and as a serverless endpoint on Zyphra Cloud. The company positions the model as an open-weight, high-efficiency reasoning option for researchers and builders; its MoE design activates just 760 million parameters per forward pass, promising a much smaller active footprint than dense models with similar capacity.
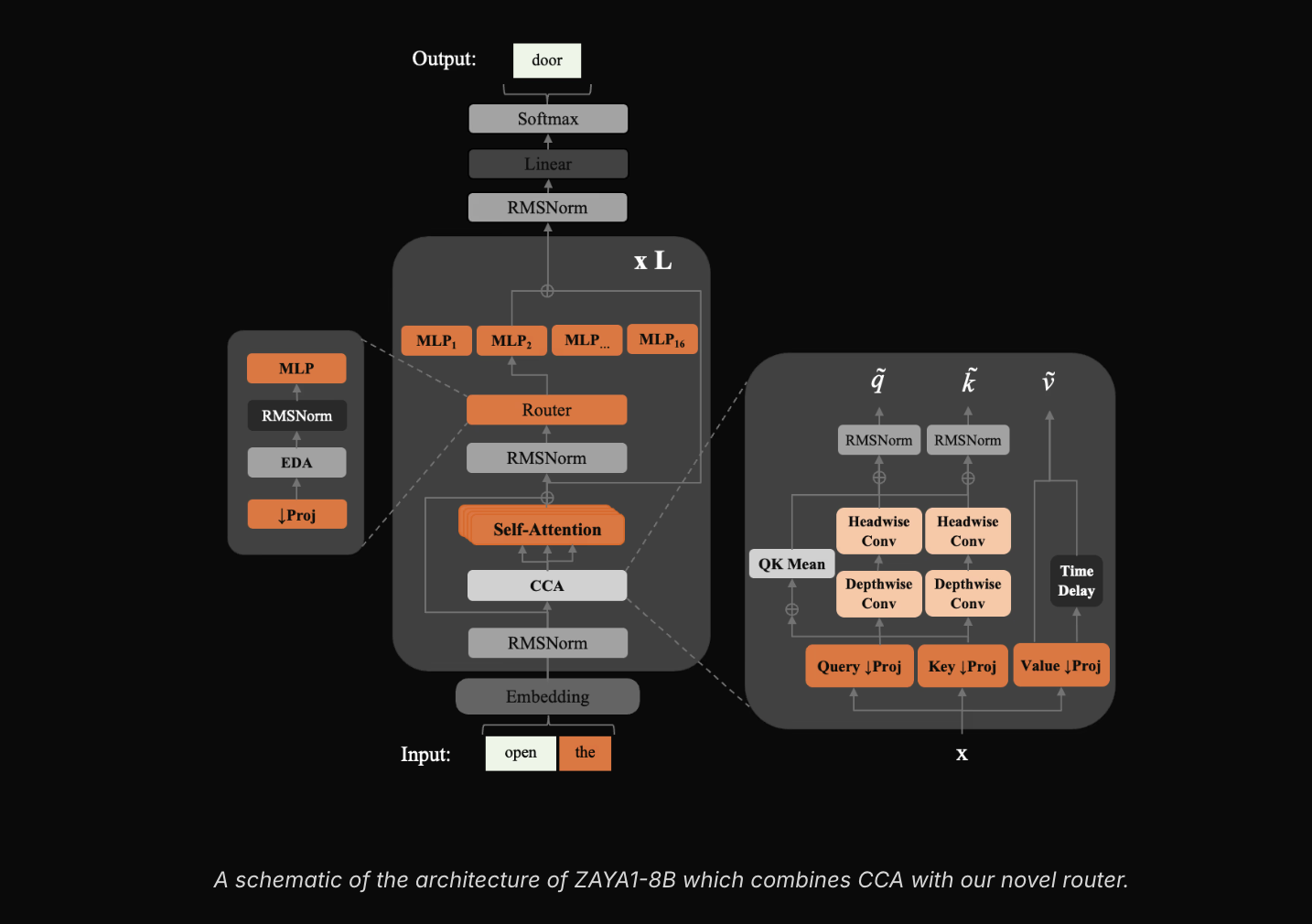
Branded MoE++, ZAYA1-8B combines its MoE topology with three core architectural innovations. Compressed Convolutional Attention (CCA) reportedly delivers roughly 8× KV-cache compression versus standard attention. An MLP-based router uses PID-controller bias balancing to stabilise expert load, and learned residual scaling controls residual norm growth while adding minimal overhead. Zyphra trained the model end-to-end on an AMD stack. The full pretraining, midtraining and supervised fine-tuning pipeline ran on a custom IBM-built cluster of 1,024 AMD Instinct MI300x nodes connected via AMD Pensando Pollara interconnect. The company emphasizes a reasoning — first pretraining approach and a five-stage post-training regimen that includes supervised fine-tuning, a reasoning warmup phase and a large RLVE gym phase with dynamically adjusted puzzle difficulty.
On benchmarks, Zyphra reports ZAYA1-8B outperforming much larger open-weight models on math and coding tasks. The model scored 89.6 on HMMT'25, ahead of Claude 4.5 Sonnet and GPT-5-High at 88.3, and Zyphra says ZAYA1-8B narrows the gap with early — generation frontier reasoning models such as DeepSeek — V3.2 while competing with Gemini-2.5 — Pro and DeepSeek — R1-0528 on challenging mathematical reasoning datasets.
For deployment, the 760M active / 8.4B total parameter split together with CCA’s KV-cache compression yields concrete inference advantages: lower compute and memory — bandwidth requirements, a reduced KV-cache footprint that enables longer effective contexts, and the potential for on-device or low-latency serverless deployments compared with similarly capable dense models. Zyphra also credits a test-time compute method called Markovian RSA with part of the model’s math gains by enabling smarter candidate aggregation at inference.
By shipping ZAYA1-8B under Apache 2.0, providing a serverless endpoint and documenting an AMD-based full-stack training run, Zyphra aims to accelerate experimentation and adoption by teams focused on per — FLOP and per-parameter efficiency. Delivering a sub-1B active — parameter MoE that competes with much larger models highlights a path for tighter hardware — model co-design and raises the bar for intelligence density in the small — model weight class.
Sources
Replies (0)
No replies in this topic yet.