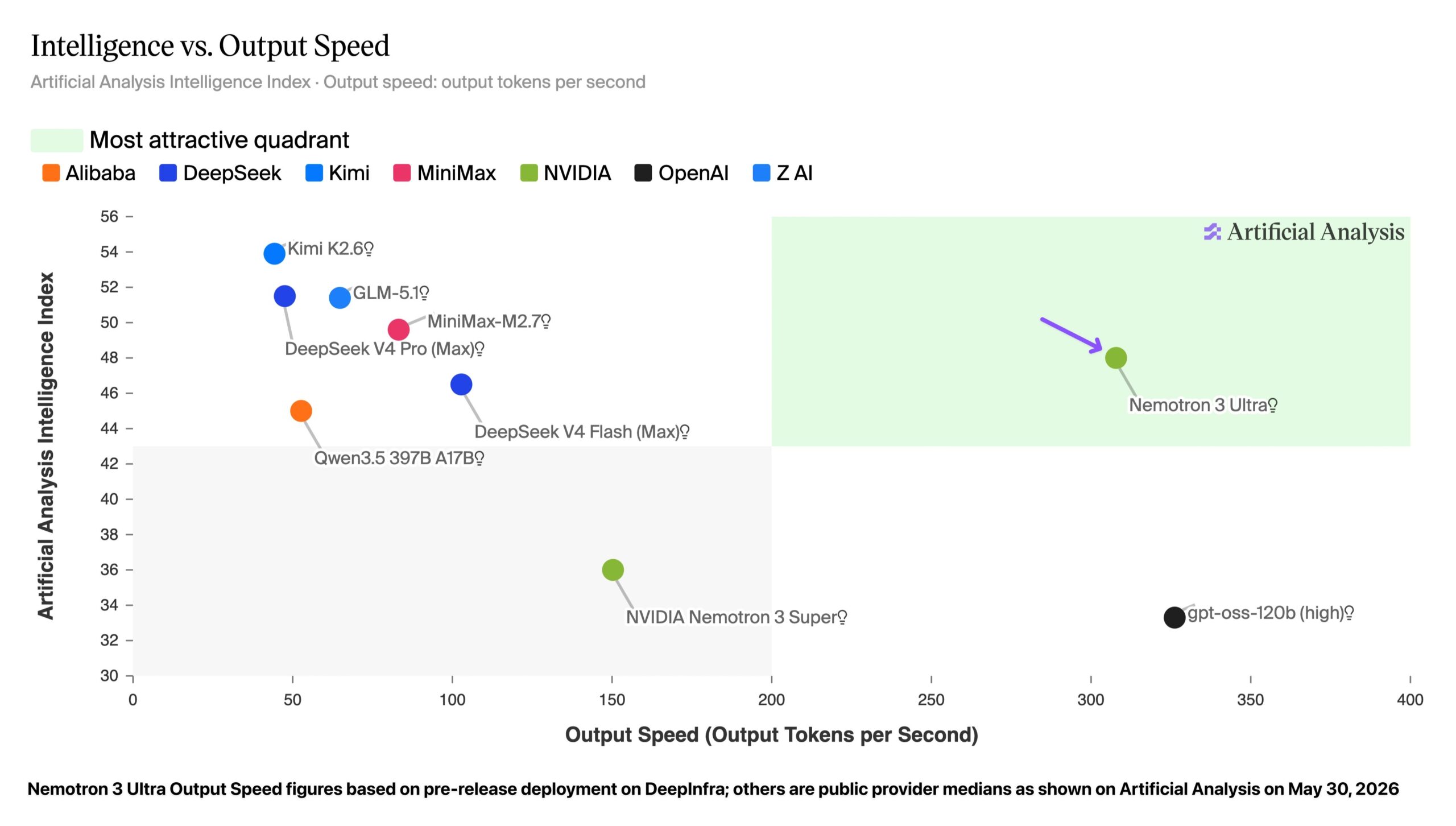
NVIDIA’s Nemotron 3 Ultra scored 48 points in Artificial Analysis’s (AAII) latest intelligence ranking, making it the highest — rated open model from U.S. organizations in that dataset and placing it in AAII’s “most attractive quadrant” where higher intelligence aligns with fast output. AAII recorded throughput above 300 tokens per second for Nemotron 3 Ultra on provider DeepInfra, a performance level that matters for latency — sensitive and cost-conscious deployments.
NVIDIA describes Nemotron 3 Ultra as a sparsely activated model with roughly 550 billion total parameters and about 55 billion active at any given time-roughly a 10% active fraction. AAII and the coverage note that sparse activation typically reduces runtime compute and memory needs compared with fully dense execution, a practical consideration when estimating hosting and inference costs.
The AAII scoreboard preserves model — by-model detail. Other open models from U.S. organizations scored lower in the same run: Gemma 4 31B received 39 points, Nemotron 3 Super scored 36, and gpt-oss-120b reached 33. By contrast, the top open models from China outscored Nemotron 3 Ultra (for example, Kimi K2.6 at 54), and the strongest closed model in AAII’s set, Opus 4.8, reached 61 points. AAII also reports that providers such as DeepSeek and Moonshot currently deliver roughly 50 — 100 tokens per second on the same infrastructure.
NVIDIA has scheduled public availability of Nemotron 3 Ultra for June 4, with distribution planned via Hugging Face, OpenRouter and other platforms, which should broaden access across cloud and third‑party hosting ecosystems. Wider availability is likely to accelerate testing and adoption by builders evaluating trade — offs between model capability, latency, and cost. The observed throughput gap — Nemotron 3 Ultra’s 300+ tps versus many providers’ 50 — 100 tps-points to performance differences either in model design, serving stacks or both. Those differences could influence short‑term provider selection for applications where latency or scale are decisive, and they create room for further optimizations that may shift competitive dynamics among hosting vendors.
Sources
Replies (0)
No replies in this topic yet.