Un equipo de investigación de ByteDance describe Lance, un modelo multimodal nativo y de código abierto que integra en un único marco comprensión, generación y edición de imágenes y video.
ByteDance ha documentado Lance, un modelo multimodal nativo y de código abierto diseñado para integrar en una sola arquitectura tareas de comprensión, síntesis y edición visuales. El equipo presenta el sistema como una solución que reúne captioning, visual question answering (VQA), OCR, text‑to‑image, text‑to‑video y edición de imagen y video, con el objetivo de unificar flujos que hasta ahora se trataban por separado. El proyecto se publica como implementación completa y artículo en arXiv.
Los autores plantean la tensión central que busca resolver Lance: por un lado están las representaciones semánticas de alto nivel necesarias para razonamiento y entendimiento; por otro, las representaciones continuas de bajo nivel requeridas para generar texturas y dinámica temporal. El diseño del modelo intenta conciliar ambos requisitos sin sacrificar la capacidad para tareas opuestas dentro de un único contexto operativo. Para organizar las salidas, Lance define tres familias funcionales: X2T (salidas de texto), X2I (imágenes) y X2V (videos). El sistema soporta desde captioning y VQA hasta generación específica de sujeto, conversión imagen→video y edición multivuelta con consistencia temporal, todo bajo un único esquema de interacción. Según el informe, Lance activa 3.000 millones de parámetros y su código y documentación están disponibles para reproducción y extensión.
Arquitectónicamente, Lance convierte texto, imágenes y secuencias de video en una única secuencia multimodal intercalada. Para embeddings de texto y entradas orientadas a entendimiento utiliza la capa Qwen2.5‑VL; el encoder ViT de Qwen2.5‑VL produce tokens visuales semánticos adecuados para tareas de comprensión. Para generación multimodal emplea un encoder VAE causal 3D Wan2.2 que crea representaciones latentes con downsampling espacial de 16× y temporal de 4×. Sobre todo el contexto aplica una atención causal 3D generalizada, con tokens de texto procesados en atención causal y tokens visuales en atención bidireccional.
Para mantener capacidades distintas sin que colisionen los parámetros, Lance introduce una mezcla de expertos (Mixture of Experts) de doble vía, iniciada desde Qwen2.5‑VL 3B. El experto de entendimiento (LLMUND) procesa texto y tokens visuales semánticos y se entrena con la pérdida clásica de predicción del siguiente token; el experto de generación (LLMGEN) procesa tokens latentes del VAE y se entrena con un objetivo de flow matching en el espacio latente continuo. Ambos comparten el contexto intercalado, pero conservan caminos de capacidad desacoplados y pérdidas combinables mediante pesos configurables.
Para distinguir en la secuencia intercalada grupos de tokens visuales que ocupan posiciones semejantes, los autores proponen Modality‑Aware Rotary Positional Encoding (MaPE). MaPE aplica un desplazamiento temporal fijo por grupo de modalidad sin alterar las coordenadas espaciales internas, de modo que separa los límites posicionales globales sin romper el orden temporal dentro de un video. En ablaciones, la eliminación de MaPE degrada consistentemente el rendimiento en varias métricas, lo que sugiere que la distinción posicional entre grupos de tokens contribuye tanto a tareas de generación y edición como a las de entendimiento.
El entrenamiento de Lance se organiza en cuatro etapas secuenciales. En Pre‑training (PT) se usaron aproximadamente 1.000 millones de pares imagen‑texto y 140 millones de pares video‑texto, acumulando 1,5 billones de tokens de entrenamiento; en esa fase los encoders VAE y ViT permanecieron congelados. La etapa de Continual Training (CT) añadió muestras multitarea intercaladas, edición y generación dirigida a sujeto sobre ~300.000 millones de tokens mediante una mezcla de datos progresiva. Supervised Fine‑Tuning (SFT) empleó ~72. finalmente, se aplicó una etapa de RL con Group Relative Policy Optimization (GRPO), usando PaddleOCR como modelo de recompensa.
El costo computacional máximo informado para todo el proceso fue de 128 GPUs. Los autores detallan cómo la combinación de fases y la mezcla de pérdidas permiten especializar comportamientos sin duplicar totalmente la base de parámetros, buscando así un balance entre capacidad, eficiencia y diversidad funcional.
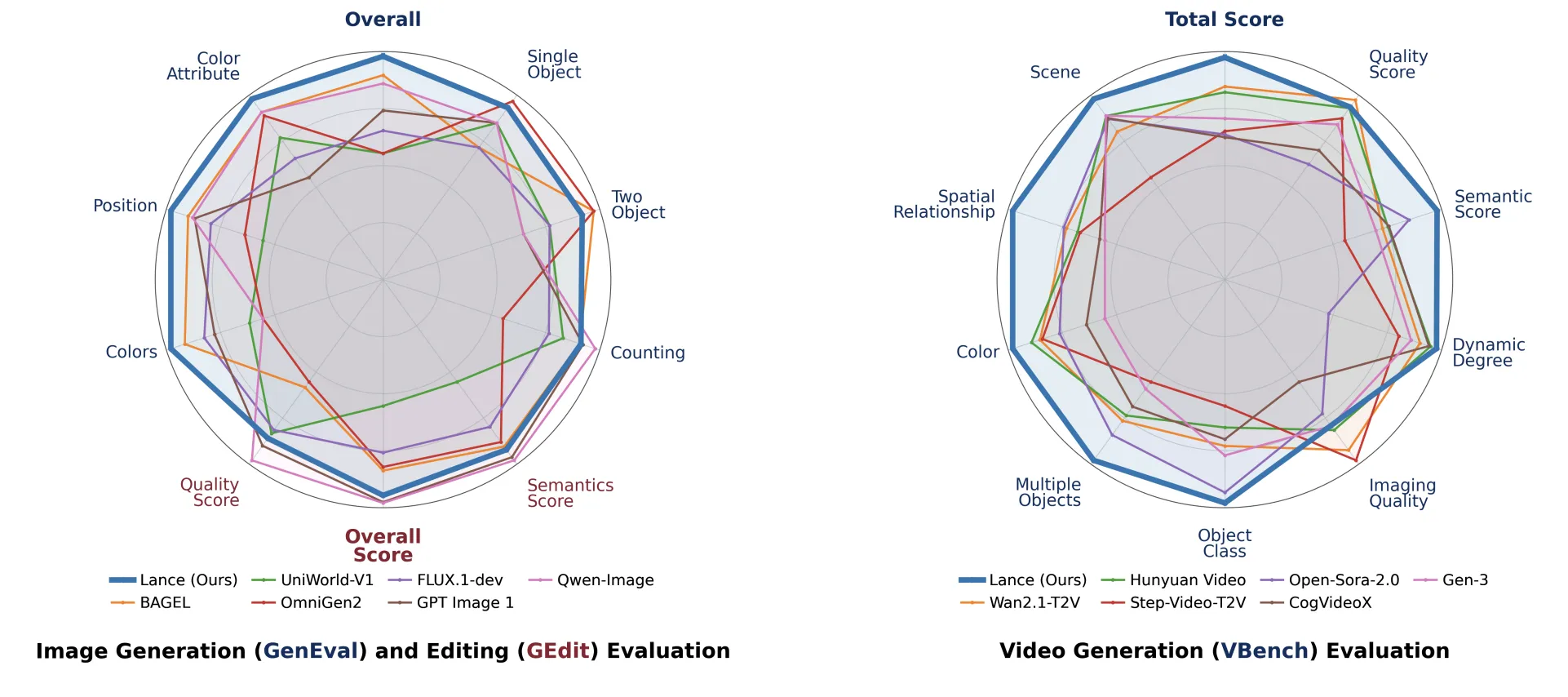
En evaluaciones de generación de imagen, Lance obtiene un puntaje global de 0,90 en GenEval, empatando con TUNA dentro del conjunto de modelos unificados; en subcategorías reporta 0,84 en conteo, 0,97 en color y 0,87 en posición espacial. En DPG‑Bench alcanza 84,67, con fortaleza en modelado de relaciones, aunque TUNA (86,76) y TUNA‑2 (86,54) lideran ese benchmark. Para comparar eficiencia de parámetros, modelos como Janus‑Pro‑7B obtienen 0,80 en GenEval y Show‑o2 (7B) 0,76, lo que subraya la eficiencia de Lance al lograr resultados competitivos con 3.000 millones de parámetros activados.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.