Fastino Labs presentó GLiGuard, un moderador de 300 millones de parámetros con arquitectura encoder que evalúa múltiples dimensiones de seguridad en una sola pasada y, según la empresa, iguala la precisión de modelos mucho mayores en pruebas estandarizadas.
Fastino Labs lanzó GLiGuard, un modelo de moderación de 300 millones de parámetros diseñado para reducir latencia y costes en aplicaciones con LLM. El anuncio destaca que GLiGuard realiza evaluaciones de seguridad en una sola pasada y que, según los datos publicados por la compañía, alcanza precisión comparable a la de modelos mucho más grandes en pruebas estandarizadas. Si esas cifras se confirman en despliegues reales, el modelo podría disminuir significativamente el coste y la latencia de los guardrails en sistemas con moderación continua.
A diferencia de la mayoría de los guardrails actuales, GLiGuard emplea una arquitectura encoder (no decoder — only) y ejecuta cuatro tareas en un único forward pass: seguridad del prompt (prompt safety), detección de estrategias de jailbreak, clasificación de categoría de daño (harm category classification) y detección de refusas (refusal detection). Esa combinación busca centralizar varias comprobaciones de seguridad sin procesar cada una de forma separada.
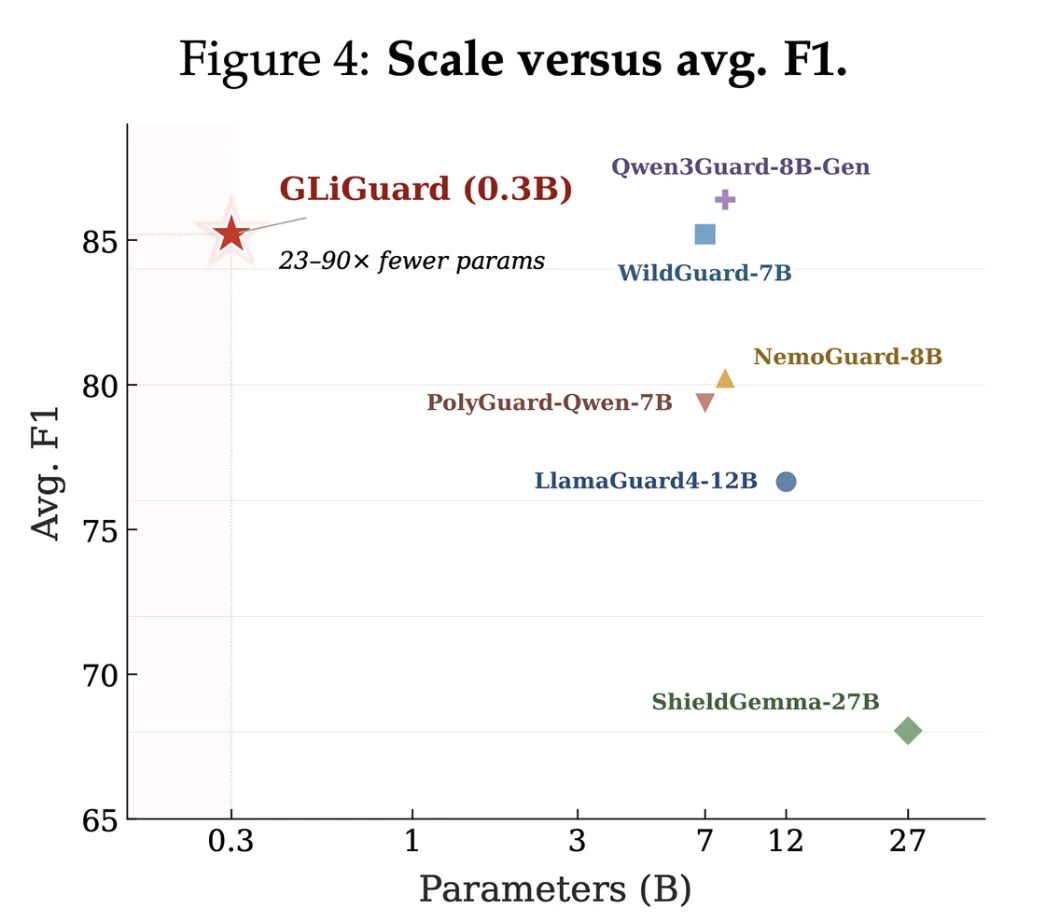
Fastino reporta que, en nueve benchmarks de seguridad, GLiGuard iguala o supera la precisión de modelos rivales entre 23 y 90 veces mayores en tamaño. La compañía presenta estos resultados como prueba de que una arquitectura más compacta y orientada a múltiples tareas puede competir con modelos autoregresivos sustancialmente mayores en métricas de seguridad.
La presentación contrasta GLiGuard con modelos decoder — only que generan veredictos de forma autoregresiva y secuencial — por ejemplo LlamaGuard4 (12B), WildGuard (7B), ShieldGemma (27B) y NemoGuard (8B)— y subraya que ese enfoque secuencial encadena latencia y costes cuando la moderación se ejecuta en cada solicitud y en cada turno de diálogo.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.