Google presentó una implementación de drafters basada en Multi‑Token Prediction (MTP) dirigida a la familia de modelos Gemma 4. La propuesta articula un flujo de trabajo en el que un modelo ligero actúa como “drafter” que genera rápidamente borradores de varias secuencias de tokens, mientras que el modelo objetivo los verifica para producir la salida final. El objetivo es reducir la latencia y el coste operativo de la generación autoregresiva sin alterar el resultado que produciría el modelo principal.
El núcleo del método es la decodificación especulativa: el drafter propone varios tokens sucesivos como un borrador y el modelo objetivo — por ejemplo, Gemma 4 31B-verifica esas propuestas en paralelo en una única pasada. Si el verificador acepta el borrador, la secuencia se valida y el modelo objetivo además genera un token extra, de modo que varias salidas aparecen en el tiempo equivalente a una sola pasada de verificación, mejorando el rendimiento de generación en aplicaciones de producción.
Para reducir la sobrecarga computacional, los drafters MTP incorporan optimizaciones arquitectónicas: los modelos de propuesta reutilizan activaciones intermedias del modelo objetivo y comparten su KV cache (la caché de claves y valores empleada en la atención). Al compartir ese estado, se evita recalcular el contexto ya procesado por el modelo mayor, lo que disminuye operaciones redundantes y reduce el tiempo por paso de generación.
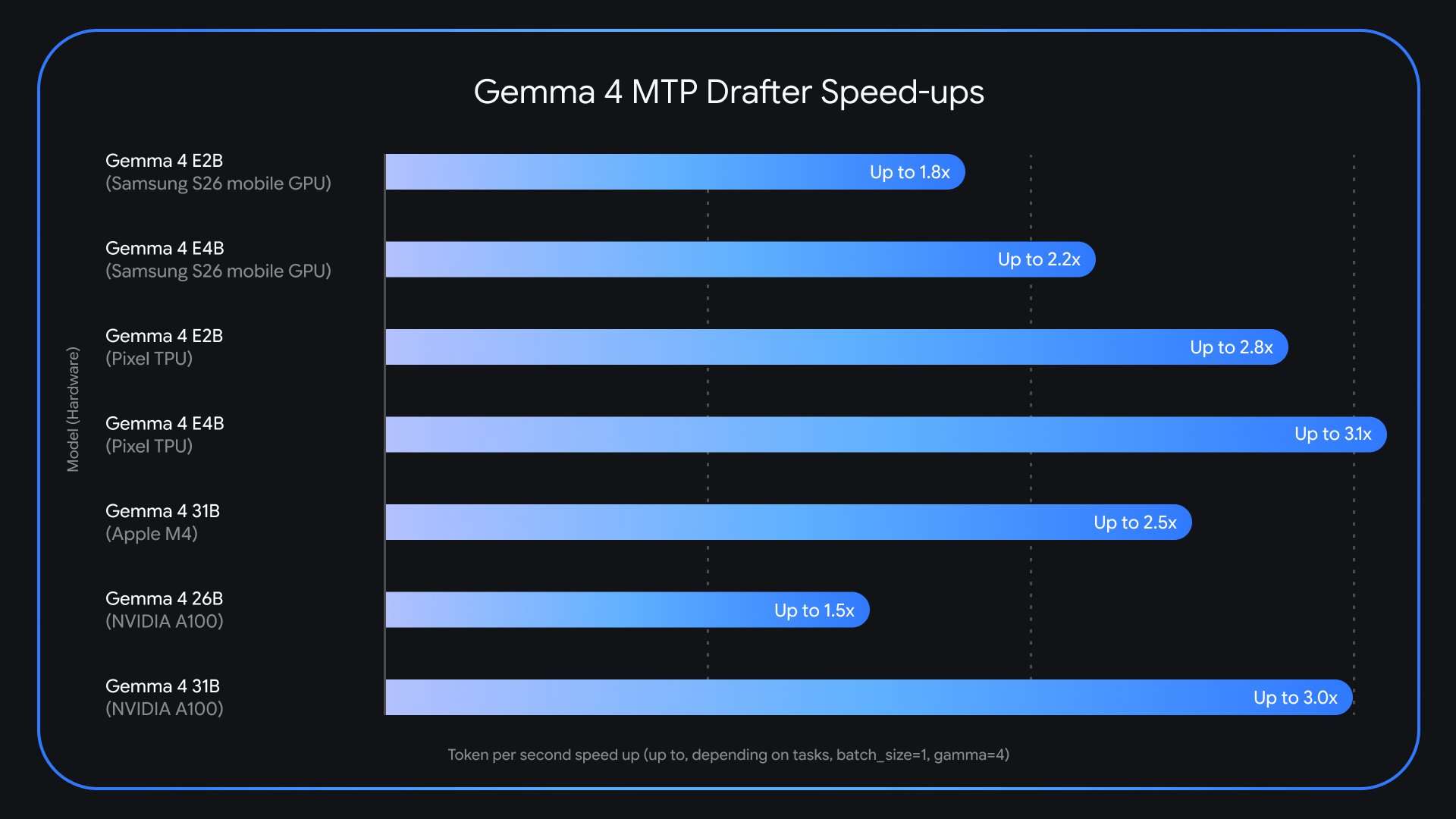
En variantes diseñadas para dispositivo móvil y edge, Google aplica técnicas de clustering en la capa de embedding de las versiones más pequeñas de Gemma 4 — conocidas como E2B y E4B-para acelerar el cálculo final de logits, un cuello de botella habitual en hardware con memoria y CPU limitadas. Esas optimizaciones permiten que el drafter funcione de forma eficiente en escenarios con restricciones de recursos sin sacrificar la compatibilidad con el flujo de verificación del modelo objetivo.
El trabajo subraya por qué esta optimización es relevante en la práctica: los grandes modelos autoregresivos generan un token por vez y cada paso exige mover miles de millones de parámetros desde la memoria a las unidades de cómputo. Ese patrón es “memory‑bandwidth bound”: la limitación principal es la velocidad de transferencia de memoria, no solo la potencia de cálculo, lo que provoca subutilización de las GPUs durante los movimientos de datos. MTP busca mitigar ese cuello de botella al reducir la frecuencia de pases completos del modelo mayor.
La presentación contextualiza el lanzamiento en la adopción reciente de la familia Gemma 4: semanas antes, Gemma 4 había superado los 60 millones de descargas, y la mejora se plantea como una respuesta directa al problema operativo más frecuente en despliegues de LLM: la latencia y el coste de la generación token‑a‑token, independientemente del hardware disponible.
En cuanto a rendimiento y calidad, Google afirma que MTP puede ofrecer hasta 3× de aceleración en inferencia sin pérdida de calidad ni de precisión de razonamiento porque la verificación final la realiza el modelo objetivo. Según esa descripción, los resultados coinciden token por token con lo que el modelo principal produciría de forma estándar, lo que convierte la técnica en una aceleración “lossless” para casos que admiten la arquitectura drafter+verificador.
El equipo también señala limitaciones y retos de despliegue: la variante Mixture‑of‑Experts Gemma 4 26B introduce complejidades de enrutamiento en Apple Silicon cuando se trabaja con batch size 1, por lo que la recomendación práctica es aumentar el batch entre 4 y 8 para mejorar rendimiento. Además, la técnica exige integrar un modelo drafter y gestionar el intercambio de caché entre modelos, requisitos operativos que deben resolverse en la infraestructura de producción.
En conjunto, los drafters MTP para Gemma 4 combinan optimizaciones de flujo y de arquitectura para atacar el problema de ancho de banda de memoria en la generación autoregresiva. La propuesta promete acelerar la inferencia de grandes modelos manteniendo la equivalencia de salida, aunque su eficacia final dependerá de ajustes en la implementación y de la adaptación a las limitaciones del hardware en cada caso.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.