Empresas de IA emplean la distilación — entrenar a un 'student' con las salidas de un 'teacher'— para trasladar razonamiento e instrucciones a modelos más pequeños y reducir costes de despliegue e inferencia.
Grandes proveedores de modelos de lenguaje están aplicando distilación para transferir capacidades de razonamiento e instrucción a versiones más pequeñas, con el objetivo de bajar costes y facilitar despliegues. En ejemplos públicos, Meta utilizó Llama 4 Behemoth para ayudar a entrenar Llama 4 Scout y Maverick; Google apoyó el desarrollo de Gemma 2 y Gemma 3 a partir de variantes de Gemini; y DeepSeek transfirió habilidades de DeepSeek‑R1 a variantes basadas en Qwen y Llama.
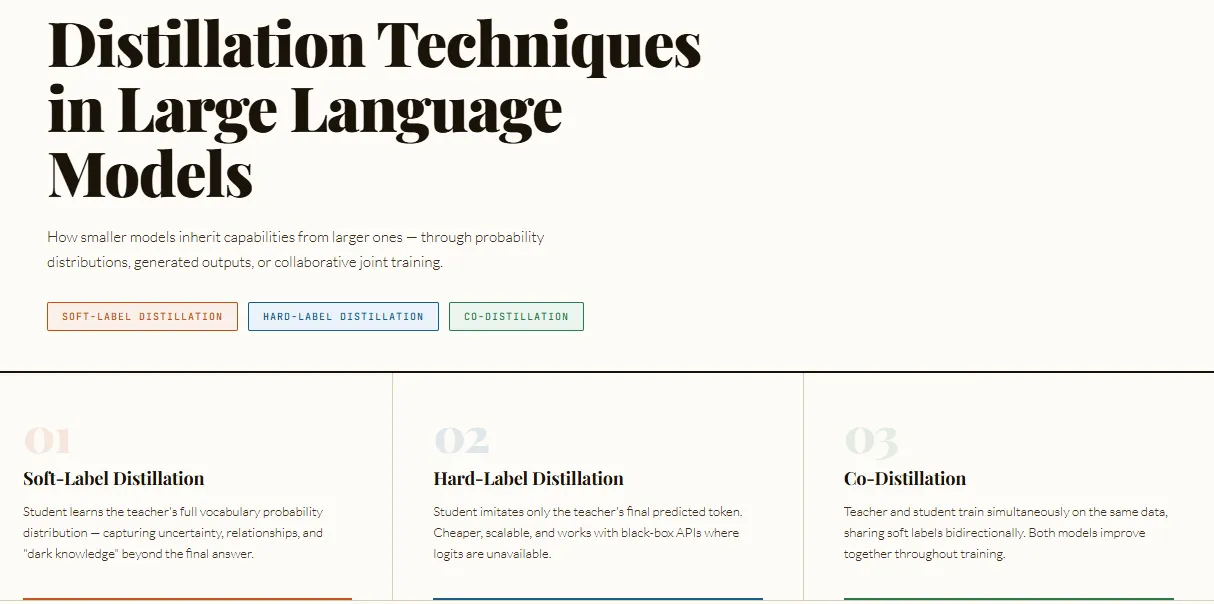
En la literatura técnica y en prácticas industriales se emplean tres enfoques principales: la distilación por soft‑labels, que entrena al student para replicar la distribución de probabilidades del teacher (p. ej., “cat” 70%, “dog” 20%, “animal” 10%) y conserva la llamada "dark knowledge"; la distilación por hard‑labels, que copia salidas concretas; y la co‑distilación, que implica un entrenamiento colaborativo entre varios modelos. La transferencia puede aplicarse tanto durante el pre‑entrenamiento como después del entrenamiento final del teacher.
Desde la perspectiva competitiva, la distilación permite que modelos más compactos hereden habilidades de razonamiento, seguimiento de instrucciones y generación estructurada sin asumir el coste computacional del teacher, lo que reduce latencia y gastos de inferencia. Por ello, equipos que buscan equilibrar rendimiento y eficiencia están adoptando estas técnicas para viabilizar despliegues en entornos con recursos limitados. Entre las limitaciones, los métodos como soft‑label requieren acceso a las probabilidades internas (logits) del teacher y pasos de cálculo adicionales para generarlas, lo que puede complicar la reproducibilidad y el flujo de trabajo de entrenamiento.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.