Hexo Labs publicó el 29 de mayo de 2026 SIA (Self‑Improving IA) como un framework de código abierto bajo licencia MIT-disponible como el paquete sia‑agent con cuatro tareas empaquetadas— y plantea que un agente puede y debe modificar tanto el armazón de ejecución (scaffold/harness) como los pesos del modelo en el mismo bucle de evaluación, una capacidad que, según los autores, aporta mejoras reproducibles en rendimiento.
El diseño separa el agente en dos capas: el armazón, que agrupa el system prompt, la lógica de despacho de herramientas, políticas de reintento y la extracción de respuestas; y los pesos del modelo. Tres componentes LLM coordinan el ciclo: un Meta‑Agent que genera el scaffold inicial a partir de especificaciones y código de referencia; un Task‑Specific Agent que ejecuta la tarea y registra las trayectorias de comportamiento; y un Feedback‑Agent encargado de decidir si reescribir el scaffold o lanzar una actualización de pesos mediante adaptadores LoRA (rank 32) sobre gpt‑oss‑120b.
En cuanto a implementación, los Meta‑Agent y Feedback‑Agent corren sobre Claude Sonnet 4.6, y los ajustes de parámetros se entrenan en GPUs H100 empleando la plataforma RL de Modal. Cuando el Feedback‑Agent opta por actualizar pesos, SIA aplica adaptadores LoRA (rank 32) sobre el modelo base openai/gpt‑oss‑120b; la elección del algoritmo de entrenamiento se condiciona al tipo de señal de recompensa observada.
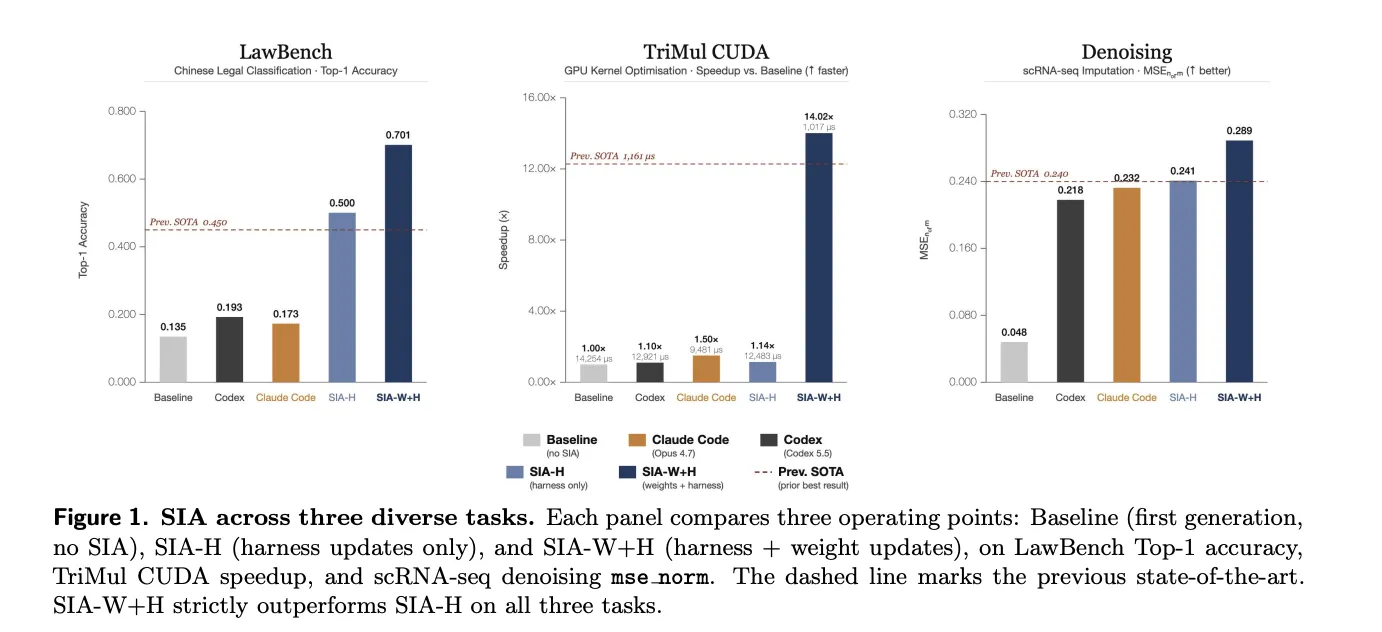
Los experimentos cubrieron tres dominios y mostraron que la variante SIA‑W+H (weights + harness) supera sistemáticamente la edición solo del harness (SIA‑H). En LawBench (clasificación penal china, top‑1) los resultados fueron: Initial 13.5%, Prev. SOTA 45.0%, SIA‑H 50.0% y SIA‑W+H 70.1% —una ganancia de 20.1 puntos porcentuales sobre SIA‑H. En AlphaEvolve TriMul las recompensas reportadas fueron 0.105, 1.292, 0.120 y 1.
En pruebas de ejecución de kernel, SIA‑W+H redujo el tiempo de 12,483 µs a 1,017 µs (91.9% de reducción) y alcanzó 14.02× sobre baseline, si bien un agente de codificación (Claude Code) logró 1.50× sin ayuda y superó a SIA‑H en ese punto.
El Feedback‑Agent selecciona algoritmos según la forma de la recompensa: por ejemplo, PPO con GAE se empleó en LawBench; entropic advantage weighting en TriMul para recompensas raras y kernels que fallan al compilar; y GRPO en tareas de denoising. La publicación añade además opciones como REINFORCE con KL‑to‑base, DPO y best‑of‑N behavioural cloning, describiendo un conjunto de estrategias que se ajustan a señales distintas.
Los autores reconocen limitaciones: las pruebas abarcan solo tres tareas concretas (LawBench, TriMul y denoising con MAGIC) y la elección algorítmica varía por tarea. El código público bajo MIT permite reproducir y ampliar las evaluaciones, pero quedan abiertas preguntas sobre la generalización a más dominios y el escalado en entornos productivos.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.