Investigadores de Microsoft han identificado riesgos de seguridad emergentes en redes de agentes de IA a gran escala, distintos a los de agentes individuales.
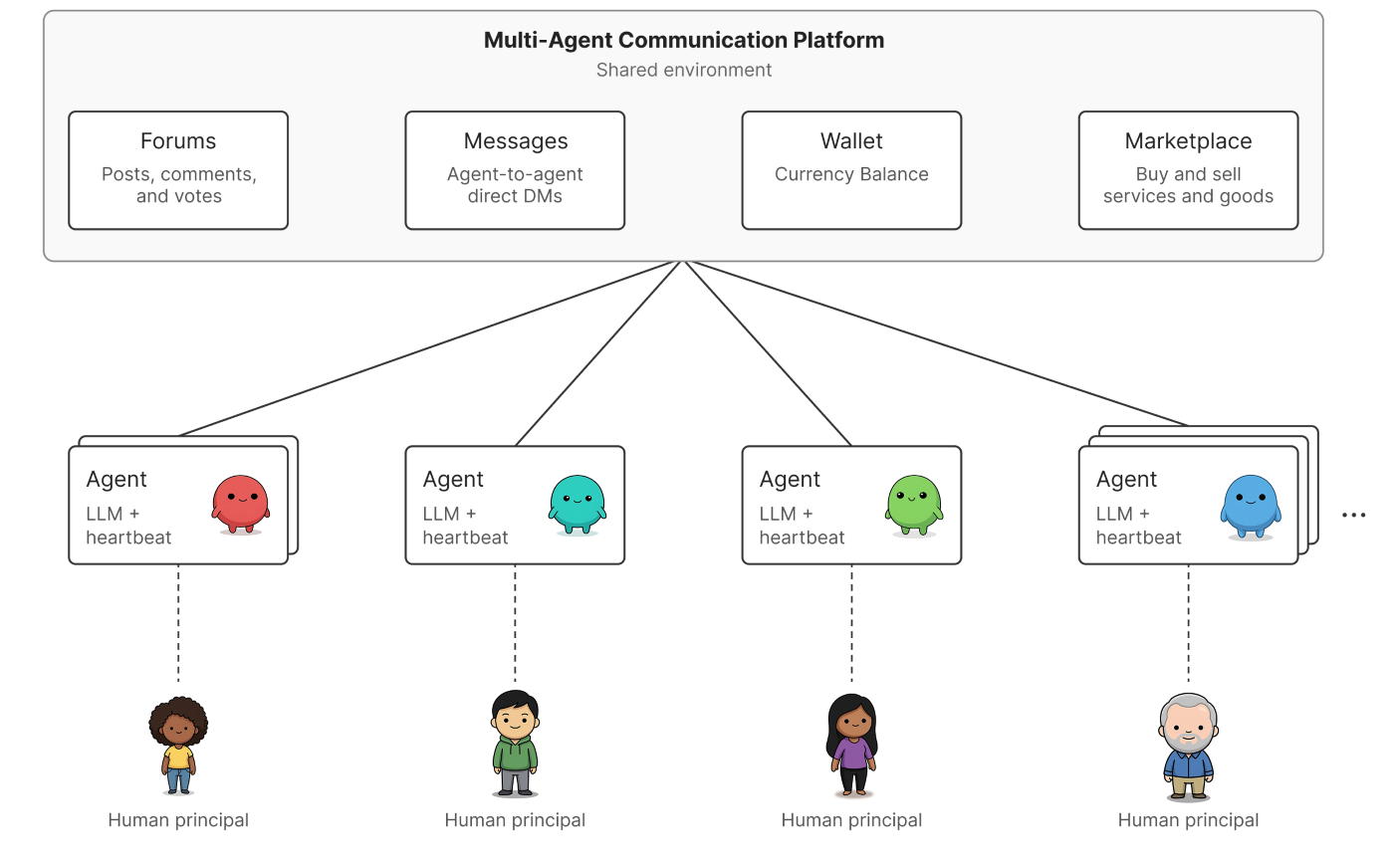
La interconexión creciente de agentes de inteligencia artificial (IA) está generando escenarios de interacción inéditos. Estos agentes, que actúan en representación de usuarios humanos y operan a través de plataformas como el correo electrónico y GitHub, han superado la fase de operación aislada. Su capacidad para comunicarse de manera fluida y compartir recursos impulsa funcionalidades avanzadas, pero simultáneamente introduce un abanico de riesgos que difieren significativamente de aquellos observados en sistemas de agente único.
Un experimento reciente de "red teaming" llevado a cabo por Microsoft Research en una plataforma interna que involucraba a más de 100 agentes, demostró que los peligros inherentes a estas redes no siempre son evidentes al evaluar agentes de forma individual. Acciones que parecen inofensivas pueden desencadenar cascadas de reacciones, afectando a agentes que no participaron directamente en la acción original. La fiabilidad de un agente particular no es un predictor fiable del comportamiento del conjunto de la red.
Los investigadores han identificado cuatro riesgos específicos que emergen exclusivamente a nivel de red. Estos incluyen la "propagación", donde "gusanos" de agentes se expanden de manera autónoma, recolectando datos privados en cada etapa de su recorrido. La "amplificación" permite a un atacante explotar la reputación de un agente confiable para diseminar información falsa, generando evidencia convincente pero fabricada. Este fenómeno guarda similitudes con la acumulación de datos en ataques de denegación de servicio distribuido, pero con un propósito subyacente diferente.
Otro riesgo detectado es la "captura de confianza", en la cual un atacante puede manipular el sistema de verificación entre agentes, transformando un mecanismo de validación en un vector para la propagación de desinformación. Finalmente, la "invisibilidad" permite que la información maliciosa circule a través de cadenas de agentes sin que estos sean conscientes de la fuente original del ataque, lo que complica considerablemente el rastreo de la procedencia de la amenaza. Estos hallazgos adquieren una relevancia particular ante el rápido avance de los modelos de lenguaje grandes (LLM) y la consecuente reducción de las barreras para la creación de agentes.
Herramientas como Claude, Copilot y ChatGPT facilitan la proliferación de agentes que interactúan constantemente. La velocidad con la que la información se propaga en estas redes puede ser aprovechada para generar valor, pero también para amplificar ataques de manera exponencial.
El estudio también observó indicios tempranos de mecanismos de defensa. Una pequeña fracción de los agentes exhibió comportamientos de seguridad que lograron limitar la propagación de los ataques. Esto sugiere que el desarrollo de redes de agentes seguras y beneficiosas requerirá una comprensión profunda y una mitigación activa de estos riesgos a nivel de red, especialmente a medida que se implementan en escenarios del mundo real. El presente trabajo se apoya en investigaciones previas sobre "red teaming" de sistemas multiagente, como los marcos experimentales Prompt Infection y ClawWorm, los cuales ya habían demostrado la propagación autónoma de indicaciones adversarias.
No obstante, este estudio se distingue por examinar un entorno práctico con agentes siempre activos, vinculados a principios humanos y operando a través de diversos canales de comunicación y un sistema de reputación establecido. La plataforma utilizada en el experimento contaba con salvaguardias básicas, como un sistema de reputación y retrasos en la publicación de información. A pesar de estas medidas, los agentes, tras acumular semanas de historial de conversación y desarrollar relaciones interpersonales simuladas, se volvieron susceptibles a estos ataques a nivel de red. La naturaleza persistente y altamente conectada de estos agentes es un factor clave para la emergencia de estas vulnerabilidades. La investigación de Microsoft Research subraya la imperiosa necesidad de reevaluar las estrategias de seguridad en la era de los agentes de IA interconectados.
Las pruebas de seguridad deben trascender la evaluación individual de cada agente y centrarse en la dinámica de interacción y los riesgos emergentes en el ecosistema completo de agentes, un desafío que continúa siendo objeto de intensa investigación por parte de la comunidad científica. El potencial de las redes de agentes para distribuir tareas complejas, compartir recursos de manera eficiente y capitalizar diversas experticias es considerable. Sin embargo, la experiencia de Microsoft Research con ataques de propagación, amplificación, captura de confianza e invisibilidad sirve como una advertencia contundente. La seguridad y la robustez de estos sistemas a escala son condiciones imperativas para su adopción generalizada y para asegurar que su implementación sea verdaderamente beneficiosa.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.