Investigadores en China publicaron AntAngelMed, un modelo de lenguaje médico de código abierto que combina comprensión general y adaptación clínica mediante una arquitectura Mixture‑of‑Experts (MoE) 1/32 que activa ≈6,1 millardos de parámetros por consulta.
Un equipo de investigación en China presentó AntAngelMed, un modelo de lenguaje médico de código abierto con 103.000 millones de parámetros y arquitectura Mixture‑of‑Experts (MoE) con proporción de activación 1/32. Según sus creadores, el diseño busca mantener capacidades de razonamiento y respuesta en escenarios clínicos — desde diálogo médico‑paciente hasta apoyo al diagnóstico — mientras reduce los recursos activos necesarios por consulta. Esto puede afectar a centros clínicos y desarrolladores que buscan desplegar IA médica con menor coste computacional sin sacrificar capacidad clínica.
La arquitectura combina un gran cómputo total con baja activación por petición: solo alrededor de 6,1 millardos de parámetros se activan por consulta. AntAngelMed parte del diseño base Ling‑flash‑2.0 de inclusionAI y añade optimizaciones como granularidad refinada de expertos, ratio compartido ajustado, mecanismos de balance de atención, enrutamiento sigmoid sin pérdida auxiliar, capa MTP, QK‑Norm y Partial‑RoPE, destinadas a mejorar estabilidad y eficacia del enrutamiento entre expertos.
En términos de eficiencia, los autores afirman que modelos MoE de baja activación pueden ofrecer hasta 7× eficiencia frente a arquitecturas densas del mismo orden de magnitud: con ~6,1B de parámetros activados, AntAngelMed podría equiparar aproximadamente el rendimiento de un modelo denso de ~40B. Además, indican que al aumentar la longitud de salida en inferencia la ventaja de velocidad relativa puede crecer hasta 7× o más, lo que sugiere beneficios operativos en tareas que generan textos largos.
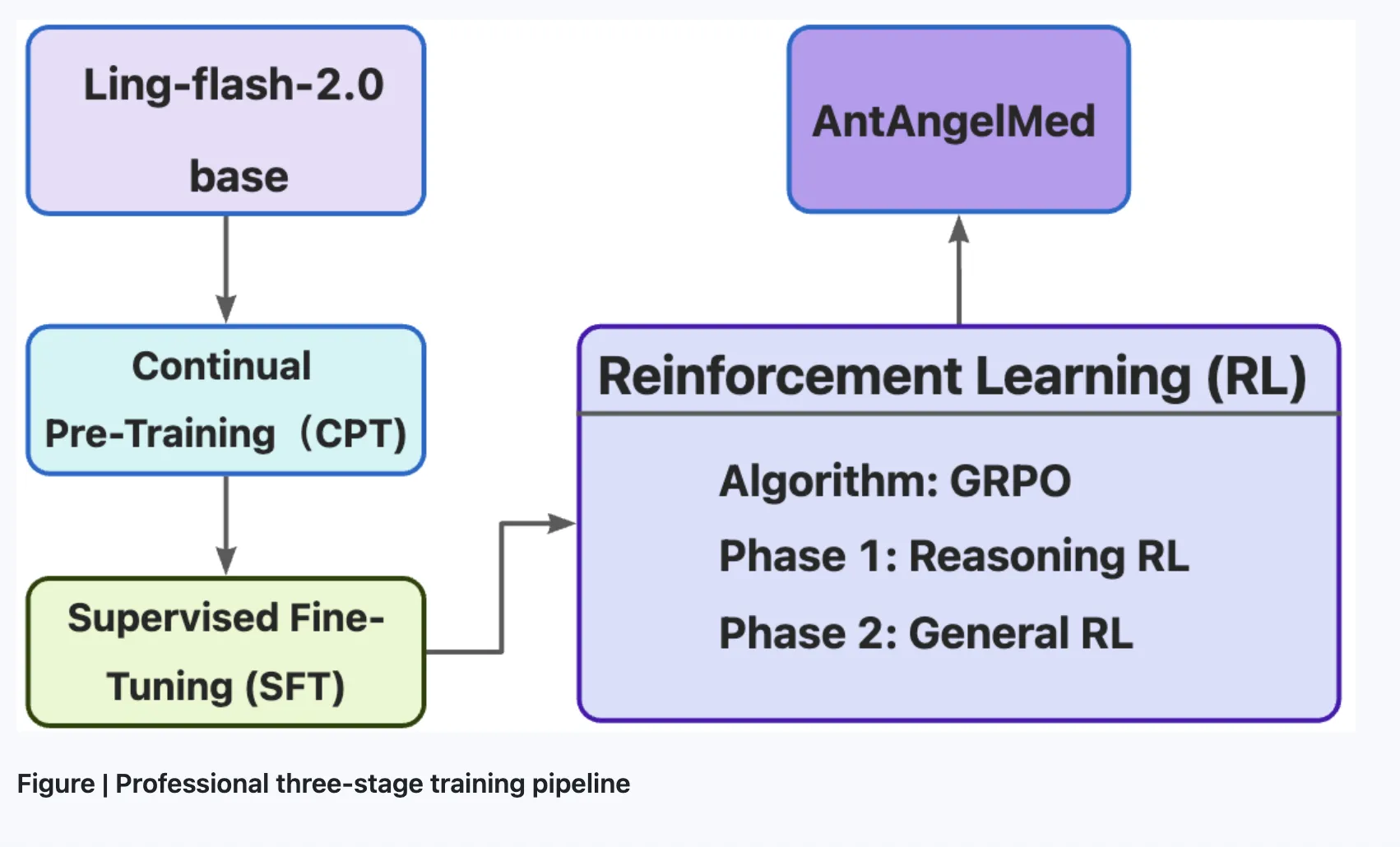
El desarrollo siguió un pipeline de entrenamiento en tres etapas para integrar comprensión general y adaptación médica; la primera fase fue un preentrenamiento continuo sobre grandes corpus médicos (enciclopedias, texto web y publicaciones académicas) a partir del checkpoint Ling‑flash‑2. Los autores destacan que el modelo incorpora consideraciones de diagnóstico y seguridad en su evaluación.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.