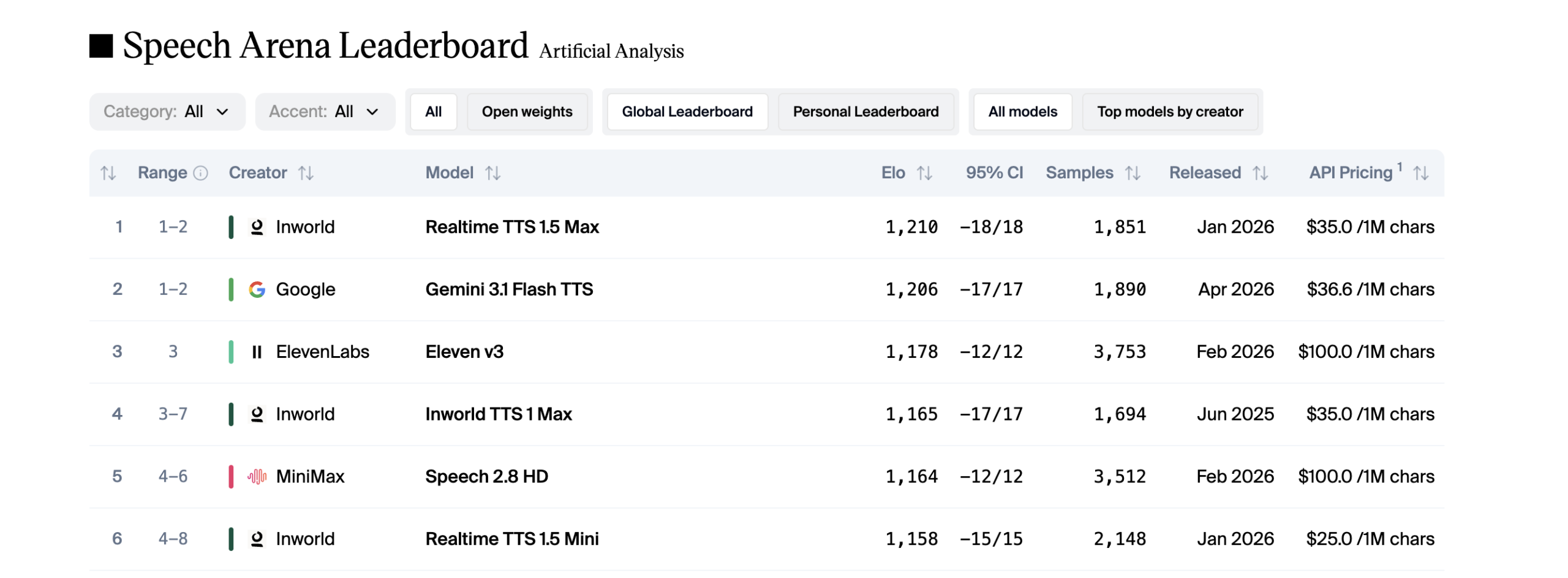
Inworld IA ha puesto en research preview Realtime TTS-2 y lo ofrece a través de Inworld API e Inworld Realtime API. La novedad clave es arquitectural: el modelo toma como entrada el audio de turnos previos dentro de una sesión Realtime en lugar de basarse únicamente en transcripciones. Ese diseño en bucle cerrado permite que la síntesis mantenga y utilice contexto de audio entre turnos sin que el desarrollador tenga que enviar campos prior_audio ni construir canalizaciones adicionales.
Al procesar audio continuo de la conversación, TTS-2 incorpora elementos como tono, ritmo y estados emocionales en la generación de la siguiente salida, lo que facilita respuestas con matices que reflejan la dinámica previa del intercambio. El sistema integra ese contexto a nivel de sesión, de modo que la entrega de la voz resultante puede alinearse mejor con sarcasmo, alivio, resignación u otras sutilezas detectables en el audio del interlocutor.
Inworld empaqueta TTS-2 con cuatro capacidades principales: Voice Direction, que permite dirigir la entonación mediante prompts en lenguaje natural y etiquetas; Conversational Awareness, la conciencia conversacional que surge del bucle cerrado; Crosslingual support, que preserva una identidad vocal coherente en más de 100 idiomas; y Advanced Voice Design, para crear y guardar voces a partir de descripciones escritas. Voice Direction admite prompts extensos y el uso de etiquetas entre corchetes para guiar la entrega en lugar de limitarse a un enum de emociones.
El motor reconoce y reproduce eventos no verbales cuando se insertan como marcadores — por ejemplo [laugh], [sigh], [breathe], [clear_throat] o [cough]— colocándolos como sucesos de audio en la salida en vez de pronunciarlos como palabras. En la capa conversacional, TTS-2 genera disfluencias naturales (uh, um), autocorrecciones, pausas a mitad de frase y pensamientos finales que imitan patrones humanos, y además tiene en cuenta que distintos perfiles de hablante agrupan los rellenos de manera diferente, reproduciendo esos ritmos característicos.
La plataforma también soporta clonación de voz mediante una API de dos pasos que comienza con la subida de una muestra de referencia, simplificando la creación de identidades vocales personalizadas. Para desarrolladores, esto supone la posibilidad de construir agentes conversacionales e IVR que respondan con mayor fidelidad emocional y control en la entrega, aplicando prompts en tiempo real para ajustar entonación y eventos no verbales. Como research preview, Inworld señala que las lenguas top-tier alcanzan calidad cercana a la de hablante nativo, mientras que la 'larga cola' de idiomas se mantiene experimental durante la ventana de lanzamiento. Por eso, la compañía recomienda probar cobertura y estabilidad antes de emplear TTS-2 en despliegues críticos.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.