JetBrains publicó Mellum2, un modelo Mixture‑of‑Experts (MoE) de 12.000 millones de parámetros con pesos liberados bajo licencia Apache 2.0, pensado como componente especializado y de baja latencia para arquitecturas que combinan varios modelos.
Qué se publicó: JetBrains presentó Mellum2 y puso a disposición los pesos del modelo bajo la licencia Apache 2.0. La compañía describe Mellum2 como un “focal model”: un componente rápido y especializado destinado a integrarse en sistemas multi‑modelo y no a sustituir a modelos de vanguardia. La liberación incluye conjuntos de checkpoints que cubren desde el preentrenamiento hasta variantes afinadas para instrucción y razonamiento.
Arquitectura y capacidades básicas: Mellum2 es un modelo Mixture‑of‑Experts con 12.000 millones de parámetros totales y, según el equipo, alrededor de 2.5B activos por token en promedio. La arquitectura utiliza 64 expertos, de los cuales se activan 8 por token, y consta de 28 capas con tamaño oculto de 2.304. Emplea Grouped‑Query Attention (GQA) con 32 cabezas de query y 4 cabezas KV, y aplica Sliding Window Attention (SWA) en tres de cada cuatro capas con una ventana de 1.024 tokens. Incorpora una cabeza de Multi‑Token Prediction (MTP), opera en precisión bfloat16 y maneja un vocabulario de 98.304 tokens. Mellum2 procesa texto y código; no es multimodal.
Extensión de contexto y diseño para largas entradas: JetBrains destacó la capacidad de contexto extendido, reportando una arquitectura con ventana de 131.072 tokens. Antes del post‑entrenamiento, el equipo amplió la ventana de contexto base a 128K tokens mediante un método selectivo denominado YaRN, con el objetivo de preservar la eficiencia del MoE al tratar secuencias largas sin sacrificar latencia en usos integrados.
Preentrenamiento y técnicas: El preentrenamiento se realizó sobre aproximadamente 10.6 billones de tokens siguiendo un currículo en tres fases que desplazó progresivamente la mezcla de datos hacia código y contenido matemático. Para optimizar el ajuste usaron el optimizador Muon con precisión híbrida FP8 y un calendario Warmup‑Hold‑Decay con decaimiento lineal hasta cero. Estas decisiones técnicas están orientadas a combinar eficiencia de cómputo y capacidad para tareas técnicas y de razonamiento.
Post‑entrenamiento y checkpoints publicados: El equipo publicó seis checkpoints que documentan todo el pipeline: Base‑Pretrain; Base (final tras la extensión de contexto); Instruct‑SFT; Thinking‑SFT; Instruct RL‑tuned; y Thinking RL‑tuned. El post‑entrenamiento siguió dos etapas principales: fine‑tuning supervisado (SFT) y ajuste por refuerzo con recompensas verificables (RLVR) aplicadas a tareas de matemáticas, código ejecutable, uso de herramientas, seguimiento de instrucciones, razonamiento y mantenimiento de conocimiento.
Modos de uso operativos: JetBrains diferencia dos variantes de interacción. La variante Instruct responde de forma directa y no externaliza cadenas de pensamiento, enfocada a escenarios de baja latencia como respuestas rápidas, uso de herramientas e instrucciones claras. La variante Thinking emite una traza explícita de razonamiento antes de la respuesta final, pensada para depuración compleja, planificación multi‑paso y flujos agentivos donde el diagnóstico interno debe ser visible.
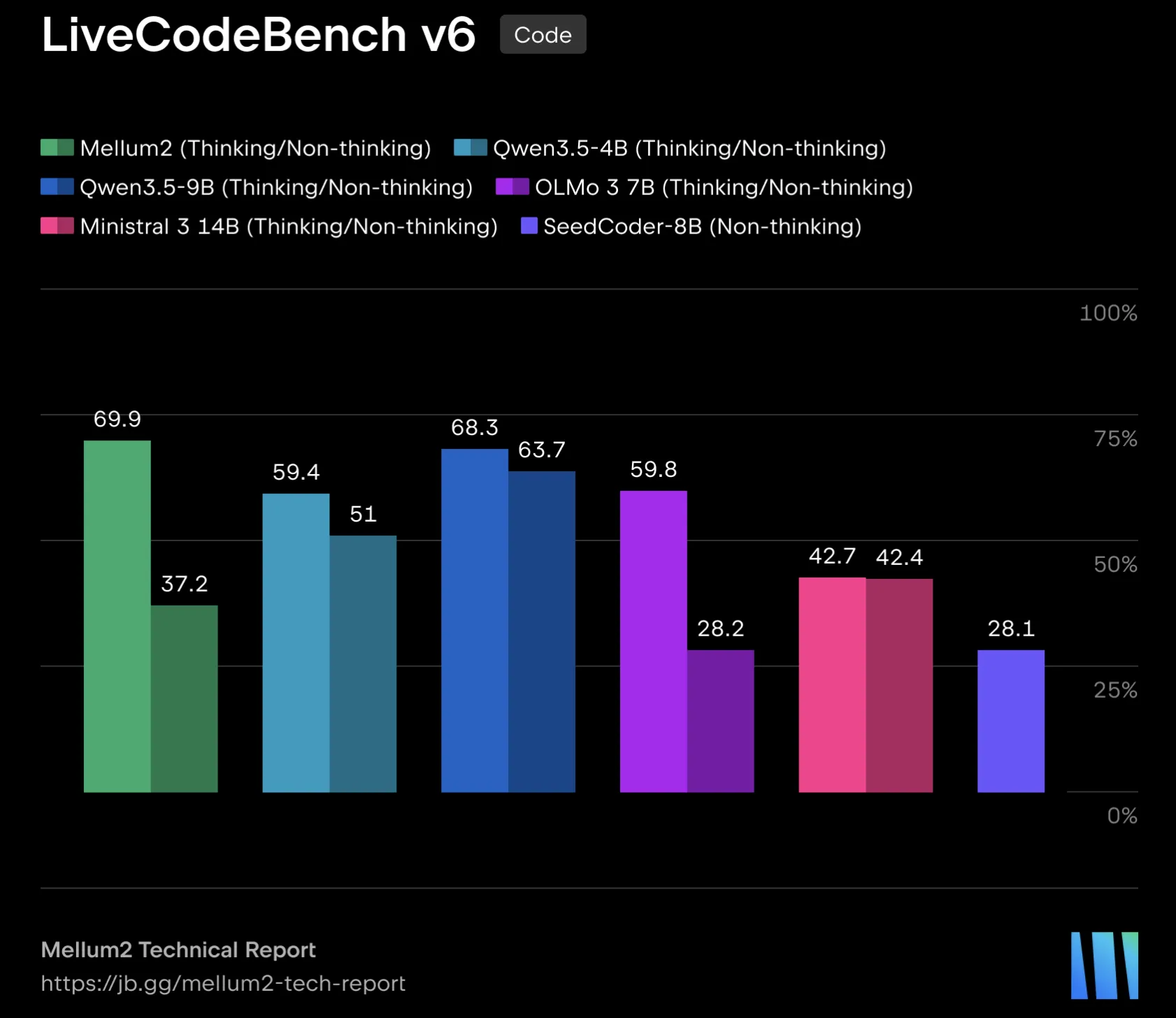
Resultados de referencia (autoinformados): En comparaciones internas frente a modelos de pesos abiertos en el rango 4B‑14B, JetBrains aportó puntuaciones por tarea en varios benchmarks: LiveCodeBench v6 37.2; EvalPlus 78.4; MultiPL‑E 67.1; BFCL v3 66.3 y BFCL v4 44.2; AIME (2025+2026) 41.7; GSM‑Plus 80.5; MMLU‑Redux 78.1; GPQA Diamond 40.9; MixEval 62.2. La comparativa incluye modelos como Qwen3.5, Ministral 3, OLMo‑3 y Seed‑Coder. JetBrains puntualiza que estos resultados son autoinformados.
Casos de producción y despliegue previstos: JetBrains identifica cuatro escenarios donde Mellum2 puede aportar valor: ruteo y orquestación (decisión entre modelos o herramientas por petición); pipelines RAG de baja latencia para resumen y generación; sub‑agentes en flujos complejos que ejecutan pasos repetitivos o sensibles a latencia; y despliegue privado o local aprovechando la licencia Apache 2.0 que permite autoalojamiento y control sobre el código y los datos.
Fortalezas prácticas destacadas: Entre las ventajas que resalta el equipo figuran la eficiencia por token propia del diseño MoE-equivalente, por token, a un modelo denso de aproximadamente 2.5B—; la cabeza MTP, que facilita decodificación especulativa sin necesidad de un modelo borrador separado; la ventana de contexto extendida; y el suministro de un conjunto completo de checkpoints para distintos usos operativos, lo que facilita integraciones en arquitecturas multi‑modelo como componente de baja latencia. Limitaciones y advertencias: JetBrains advierte que Mellum2 no sustituye a modelos de frontera y que no procesa entrada multimodal (imagen o video). Además, los resultados de benchmarks divulgados provienen del propio equipo, por lo que la integración en entornos reales exige evaluar cuidadosamente trade‑offs de precisión, latencia y coste antes de desplegar a escala.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.