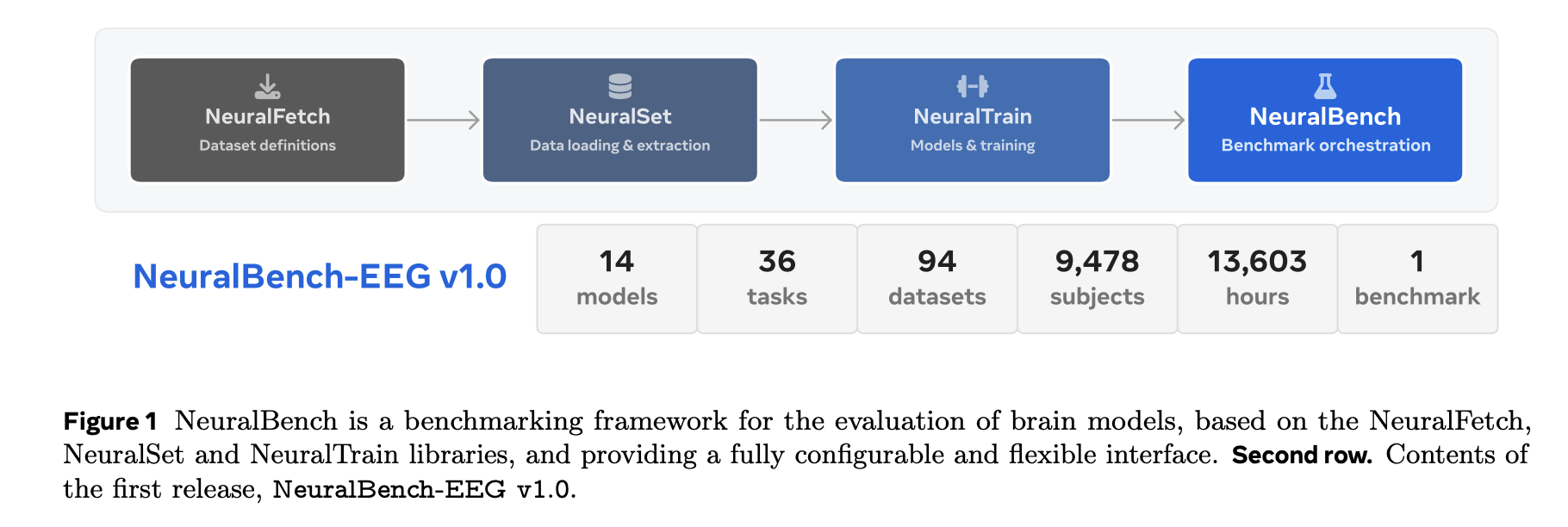
Meta IA publicó NeuralBench y su primer paquete específico, NeuralBench — EEG v1.0, con el objetivo de unificar la evaluación de modelos que procesan señales electroencefalográficas. El lanzamiento consolida 36 tareas y 94 conjuntos de datos que suman 9.478 sujetos y 13.603 horas de señales EEG, y ofrece pruebas comparativas de 14 arquitecturas bajo la misma interfaz para facilitar comparaciones reproducibles.
El marco es modular y está implementado en Python mediante tres paquetes: NeuralFetch (adquisición de datos desde repositorios públicos), NeuralSet (preparación de datos como dataloaders listos para PyTorch e integración con herramientas como MNE‑Python y nilearn) y NeuralTrain (código de entrenamiento modular sobre PyTorch Lightning, Pydantic y la librería exca). La instalación se realiza con pip install neuralbench y la ejecución se controla por línea de comandos: descargar, preparar caché y ejecutar los experimentos.
La versión EEG organiza las tareas en ocho categorías: decodificación cognitiva (con subtipos imagen, frase, habla, escritura, vídeo y palabra), interfaces cerebro‑ordenador (BCI), respuestas evocadas, tareas clínicas, estado interno, sueño, fenotipado y varias adicionales. Esa diversidad busca evaluar capacidades que van desde la decodificación de estímulos hasta aplicaciones clínicas y de sueño.
NeuralBench evalúa tres clases de modelos: arquitecturas específicas de tarea con tamaños aproximados de 1,5K a 4,2M parámetros; modelos fundacionales de EEG con rangos de 3,2M a 157,1M parámetros; y baselines basados en características manuales (representaciones SPD combinadas con regresión logística o Ridge). La comparación bajo una misma interfaz permite medir diferencias de rendimiento entre modelos especializados, fundacionales y enfoques tradicionales.
El framework normaliza la configuración experimental: cada tarea se describe mediante un archivo YAML que especifica la fuente de datos, las particiones train/val/test, los pasos de preprocesamiento, el procesamiento del objetivo, los hiperparámetros y las métricas. Todos los modelos fundacionales se entrenan con una receta compartida (optimización AdamW, lr=1e‑4, weight decay=0.05, cosine annealing con 10% de warmup, hasta 50 épocas con early stopping y patience=10); la excepción es BENDR, que se ajusta con lr=1e‑5 y clipping de gradiente en 0.5.
El valor práctico de NeuralBench radica en reducir la fragmentación de la evaluación en NeuroAI: antes existían benchmarks como MOABB-que admite hasta 148 conjuntos BCI pero restringe la evaluación a unas 5 tareas— y otros esfuerzos con limitaciones (EEG‑Bench, EEG‑FM‑Bench, AdaBrain‑Bench), mientras que para modalidades como MEG o fMRI no hay un benchmark sistemático equivalente. NeuralBench facilita reproducir experimentos, comparar modelos fundacionales frente a arquitecturas específicas y baselines, y ejecutar flujos estandarizados gracias a NeuralFetch (datos desde repositorios como OpenNeuro, DANDI y NEMAR), NeuralSet y la interfaz CLI, ofreciendo un punto de referencia único para validar afirmaciones sobre generalización y acelerar ajuste fino y evaluación a escala.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.