Investigadores de Meta FAIR, Stanford y la University of Washington anunciaron tres técnicas de inferencia destinadas a acelerar el Byte Latent Transformer (BLT). Según los autores, las propuestas reducen el consumo de ancho de banda de memoria en más del 50% y evitan la tokenización por subpalabras; en consecuencia, acortan la latencia de serving sin sacrificar la capacidad de procesar datos sin presegmentación. Este cambio resulta relevante porque facilitaría el uso de modelos que trabajan a nivel de byte en entornos productivos.
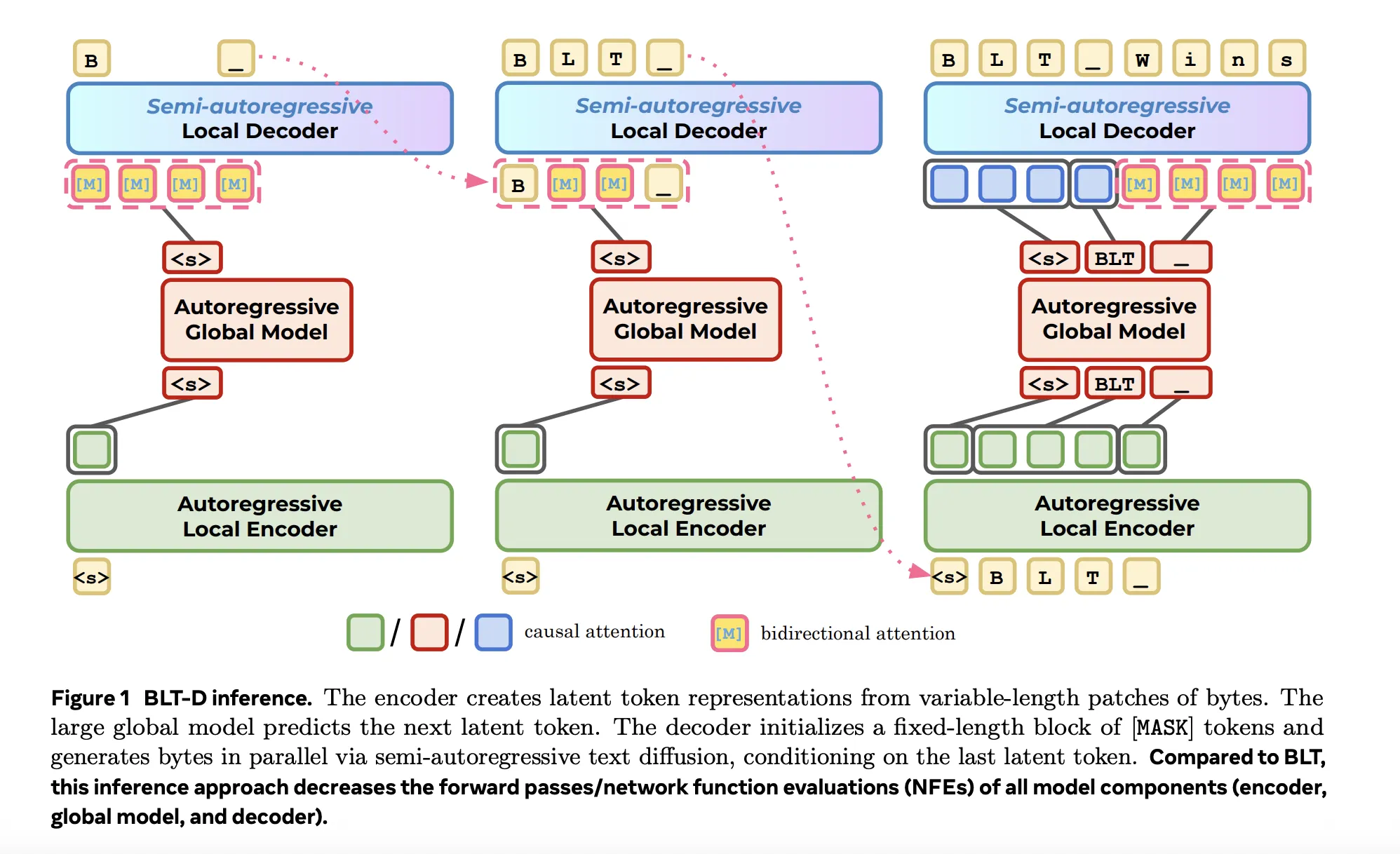
El BLT procesa directamente bytes agrupándolos en parches de longitud variable mediante una segmentación basada en entropía. Su arquitectura combina un codificador local, un gran Transformer global y un decodificador local; los parches tienen una longitud media de 4 bytes y un máximo de 8. En el entrenamiento se alimentan secuencias limpias y corruptas de bloques, y para cada bloque se muestrea un tiempo de difusión t∼U(0,1), siguiendo el esquema de difusión discreta descrito por los autores.
El trabajo identifica un cuello de botella práctico: aunque BLT alcanza rendimientos comparables a modelos con tokenización a escala, la generación autoregresiva a nivel de byte obliga a ejecutar múltiples pases del decodificador. Esos pases incrementan las lecturas y escrituras de memoria — tanto de pesos como de cachés—, de modo que la latencia en serving depende más del ancho de banda de memoria que del cálculo bruto en los aceleradores.
Las tres técnicas propuestas actúan sobre ese punto crítico al reducir el número de pases del decodificador y las lecturas de memoria, sacrificando en cada caso un grado distinto de calidad por velocidad. Entre las opciones discutidas aparece BLT-D como una de las variantes evaluadas; los autores presentan comparativas cuantitativas y análisis de compromiso velocidad — calidad. Para detalles experimentales, métricas precisas y evaluaciones completas, los autores han publicado el documento técnico en arXiv.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.