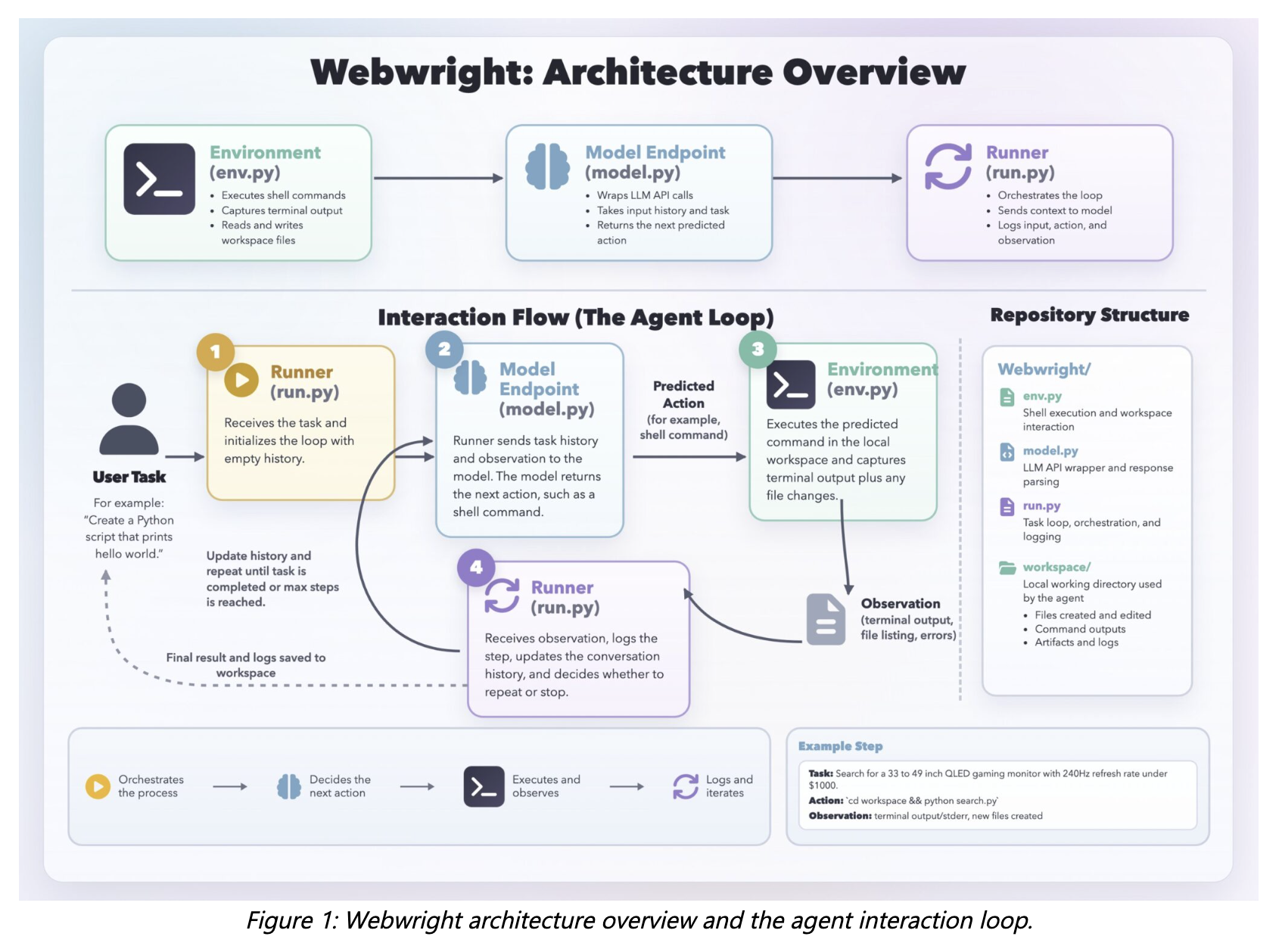
Microsoft Research ha publicado Webwright, un marco de agente web que cambia el paradigma habitual de agentes que simulan interacciones punto a punto en navegadores. En lugar de predecir clics o pulsaciones individuales, Webwright opera desde un terminal y hace que el agente escriba, depure y ejecute scripts Playwright en un espacio de trabajo local, lo que permite iteración y reutilización del código generado. La arquitectura de Webwright se compone de tres módulos principales: Runner, Model Endpoint y Environment. El proyecto suma aproximadamente 1.000 líneas de código distribuidas en estos componentes — el Runner ocupa alrededor de 150 líneas, la interfaz del modelo unas 550 y el entorno cerca de 300—; diseño que subraya su intención de ser un bucle de agente simple y auditabl e.
El flujo operativo exige que el agente genere bloques de código Playwright y, cuando procede, comandos bash. Esos comandos se ejecutan en el Environment y todos los artefactos — código fuente, capturas, registros y tracebacks — se guardan en la carpeta de trabajo. Playwright, la biblioteca empleada para controlar navegadores, soporta Chromium, Firefox y WebKit, lo que permite probar interacciones en motores web distintos.
En pruebas públicas, el equipo evaluó Webwright en dos benchmarks: Online — Mind2Web y Odysseys. Alimentado por GPT‑5.4, Webwright alcanzó 86.67% en Online — Mind2Web, lo que aparece como la puntuación más alta entre recetas de harness abiertas en AutoEval con un presupuesto de 100 pasos, y 60.1% en Odysseys. Ese resultado supera el mejor registro anterior en el tablero de abril de 2026, donde Opus 4.6 había obtenido 44.5. La ventaja central del enfoque es permitir que el agente produzca programas compactos con estructuras como bucles y funciones. Esa capacidad facilita interacciones multi‑paso-por ejemplo, rellenar formularios complejos o realizar secuencias dependientes de estado— y fomenta la reutilización de scripts entre tareas, reduciendo la fragilidad y la repetición que suelen acompañar a agentes que generan acciones primitivas coordenada‑a‑coordenada.
El bucle interno funciona así: en cada iteración el Runner envía el contexto actual al Model Endpoint; el modelo devuelve un bloque de razonamiento junto con un comando shell o un script Playwright, que se ejecuta en el Environment; la salida resultante — terminal, registros, capturas, tracebacks — se incorpora de nuevo al contexto y la iteración continúa. Para mitigar falsos positivos, el sistema obliga al agente a producir una configuración de autorreflexión y a ejecutar un script final en una carpeta limpia con evidencias antes de marcar una tarea como completa.
Los desarrolladores identificaron dos problemas de ingeniería críticos: cierres prematuros (marcar 'done' erróneamente) y la explosión del contexto por trayectorias largas de código. Para reducir esos riesgos se implementó la compactación del historial cada 20 pasos en un resumen y se exigió una verificación final automática con logs y capturas. Estas medidas disminuyen errores debidos a acciones abiertas en bash y acotan el crecimiento del contexto durante iteraciones extensas.
El análisis de coste y uso de pasos comparó modelos: Claude Opus 4.7 resuelve tareas con menos pasos medios (21.9) frente a GPT‑5.4 (26.3), pero su precio por token es mayor (a abril de 2026: $5 vs $2.50 por 1M tokens de entrada y $25 vs $15 por 1M tokens de salida). Esa diferencia eleva el coste medio por tarea a aproximadamente $6.09 para Opus frente a $2.37 para GPT‑5.4. Además, los resultados muestran que los primeros 50 pasos entregan alrededor del 82% de la precisión total, y los siguientes 50 pasos aportan solo 3–4 puntos adicionales, lo que informa decisiones de presupuesto de pasos.
Los investigadores también exploraron el uso de modelos más pequeños y bibliotecas de herramientas reutilizables. En particular, Qwen3.5‑9B combinado con colecciones preconstruidas de scripts y utilidades alcanzó 66.2% en Online — Mind2Web en sitios que ofrecían más de cinco herramientas reutilizables. Esto sugiere que, en dominios con recursos reutilizables, modelos compactos pueden abordar tareas complejas si se les provee una infraestructura de scripts adecuada.
Webwright simplifica la orquestación al operar como un único bucle de agente y mantiene todos los artefactos en el workspace para inspección y auditoría. Al mismo tiempo, depende de un manejo explícito del contexto y de la verificación automática para evitar cierres falsos y garantizar trazabilidad. Microsoft Research ha publicado el marco y una guía práctica, incluida una rápida introducción (quick start), para reproducir los experimentos y examinar los registros y scripts utilizados en las evaluaciones.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.