El 5 de mayo de 2026 Mistral IA hizo pública Voxtral TTS, su primer modelo de texto a voz, y simultáneamente liberó los pesos en Hugging Face y habilitó una API pública para acceso directo. La compañía describe Voxtral como una solución orientada a mejorar la expresividad en tareas de clonación de voz, con especial foco en mantener la identidad del hablante a lo largo de enunciados largos y en varios idiomas.
Arquitecturalmente, Voxtral reúne tres componentes que suman aproximadamente 4.0 billones de parámetros: un backbone decodificador de 3.4B parámetros, un transformador acústico flow‑matching de 390M y un códec neural de 300M. Según Mistral, el sistema puede recrear la voz de un hablante en nueve idiomas a partir de muestras de referencia tan cortas como tres segundos; en evaluaciones multilingües reportadas alcanzó una tasa de victoria del 68.4 % frente a ElevenLabs Flash v2.5.
Mistral atribuye la pérdida de naturalidad en sistemas previos a lo que denomina la “brecha de expresividad”: las señales semánticas y acústicas de la voz presentan propiedades estadísticas diferentes que dificultan un único enfoque de modelado. Forzar un único método suele implicar concesiones en la coherencia temporal o en el detalle acústico, lo que, según la compañía, ha limitado la calidad de agentes conversacionales y pipelines de producción de audiolibros.
Voxtral busca mitigar ese compromiso separando responsabilidades entre sus módulos: el sistema pretende preservar la coherencia del hablante en escalas temporales largas mediante un decodificador autoregresivo centrado en la estructura semántica, y al mismo tiempo delegar la generación fina de texturas vocales al motor acústico flow‑matching para recuperar riqueza y matices. Si las métricas humanas y de producción se confirman en entornos de uso real, el diseño podría facilitar pipelines multilingües y aplicaciones de clonación capaces de resistir escrutinio humano.
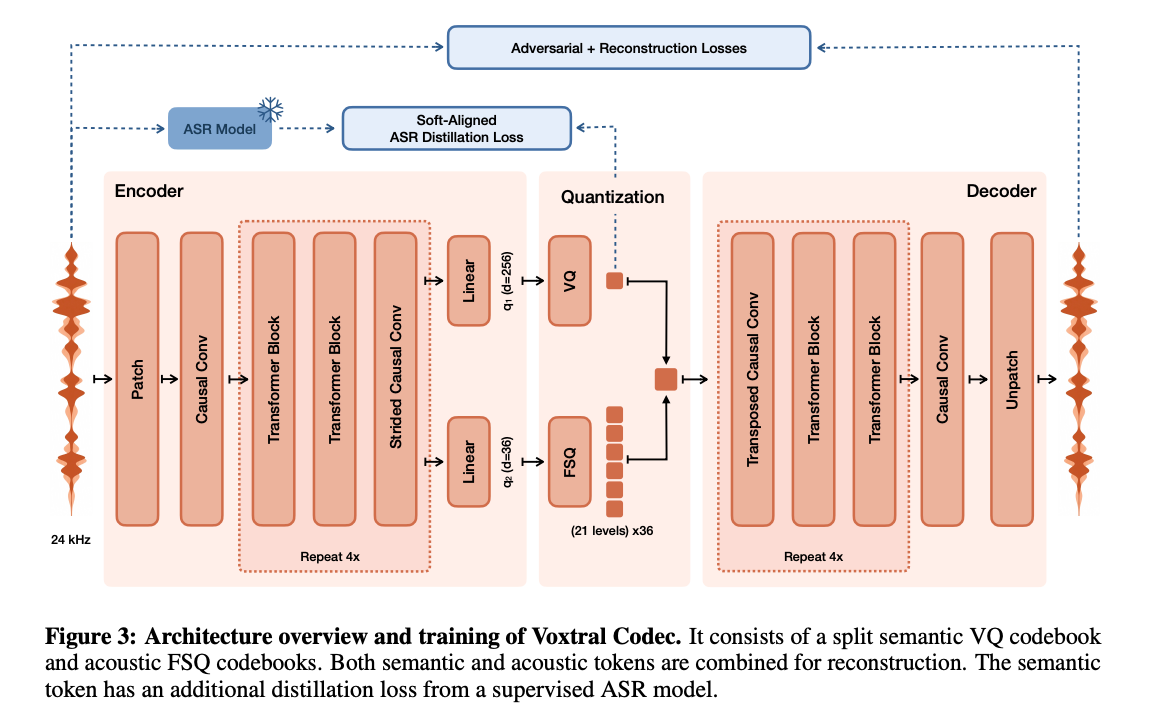
El códec neural de Voxtral actúa como tokenizador y compresor: toma una señal mono a 24 kHz y la convierte en marcos a 12.5 Hz (un marco cada 80 ms). Cada marco produce 37 tokens: un token semántico obtenido por Vector Quantization con un codebook de 8.192 entradas, y 36 tokens acústicos cuantizados por Finite Scalar Quantization con 21 niveles por dimensión. El bitrate total declarado es de aproximadamente 2.14 kbps. Además, el token semántico se entrenó mediante destilación usando como objetivo un modelo Whisper congelado.
El backbone es un transformer sólo decodificador inicializado desde Ministral 3B y actúa como el componente autoregresivo que orquesta la síntesis. En la entrada se anteponen los tokens derivados del audio de referencia y, seguidamente, el texto objetivo; el decodificador genera un token semántico por marco (cada 80 ms) de forma autoregresiva y finaliza con un token especial de fin de audio. Este flujo está pensado para anclar la identidad del hablante a lo largo de frases extensas y evitar deriva vocal.
La predicción fina de textura vocal recae en un transformador bidireccional de tres capas que opera en espacio continuo mediante flow‑matching y emplea classifier‑free guidance (CFG). La generación parte de ruido gaussiano y utiliza ocho evaluaciones de función (NFEs) con el integrador de Euler y un factor de guidance α = 1.2; los valores continuos resultantes se discretizan a los 21 niveles FSQ antes de alimentar el siguiente paso autoregresivo. Este diseño combina la flexibilidad del modelado continuo con la compatibilidad del pipeline tokenizado.
En pruebas de ablación internas, Mistral informa que el enfoque flow‑matching superó alternativas como MaskGIT y un Depth Transformer en expresividad percibida por evaluadores humanos. La compañía subraya además una ventaja de eficiencia: un Depth Transformer exigiría 36 pasos autoregresivos por marco, mientras que el transformador basado en flow‑matching requiere solo ocho NFEs, reduciendo de forma notable el cómputo por cuadro acústico sin sacrificar textura.
Respecto al entrenamiento y despliegue, Voxtral recibió primero un preentrenamiento con pares audio‑transcripción y, posteriormente, un post‑entrenamiento con Direct Preference Optimization (DPO) adaptado al objetivo flow‑based para atenuar la sensación robótica. Mistral comunica además que, en su prueba interna, una sola GPU NVIDIA H200 puede servir a más de 30 usuarios concurrentes con latencias inferiores a 600 ms. Los pesos abiertos y la API pública permiten a investigadores y desarrolladores evaluar el modelo y replicar las pruebas informadas por la compañía.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.