Nous Research ha presentado Lighthouse Attention, un mecanismo de atención jerárquico basado en selección que se aplica exclusivamente durante el preentrenamiento y se elimina para la inferencia. En ensayos sobre un modelo estilo Llama‑3 de 530 millones de parámetros con contexto de 98K tokens, Lighthouse registró una aceleración end-to-end de entre 1,40× y 1,69× frente a un baseline de scaled dot‑product attention (SDPA) respaldado por cuDNN, sin aumentar la pérdida final.
Esto puede reducir costes de computación y facilitar entrenamientos con contextos muy extensos manteniendo el modelo denso de inferencia sin cambios.
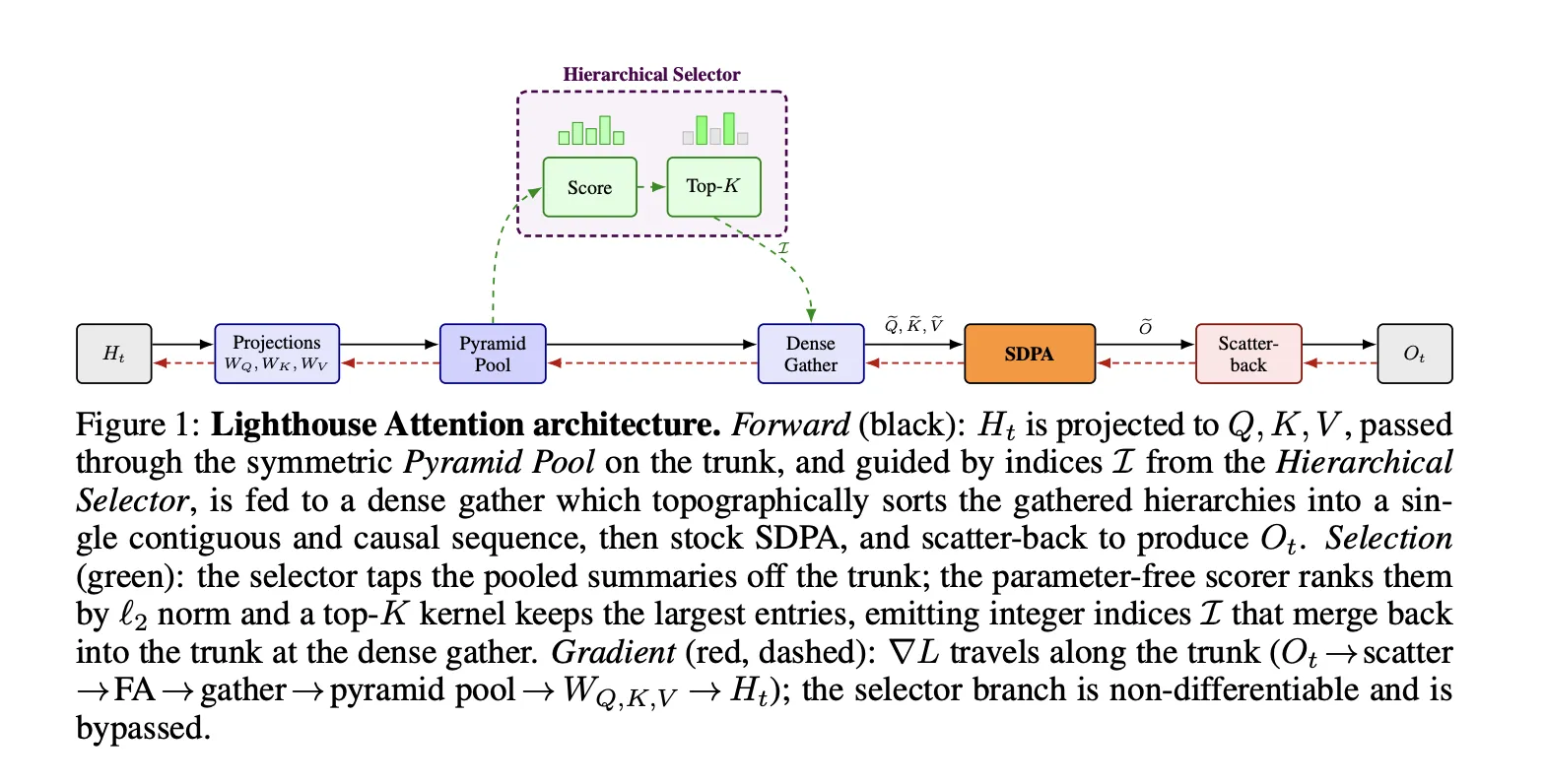
La técnica envuelve la scaled dot‑product attention sin modificar su núcleo y opera mediante un pipeline de cuatro etapas. Primero construye una pirámide multi‑resolución por pooling aplicando la misma operación sobre Q, K y V con coste Θ(N). A continuación puntúa sin parámetros las entradas de la pirámide, selecciona subconjuntos y reúne las entradas elegidas en una subsecuencia densa; finalmente ejecuta el kernel estándar FlashAttention sobre esa subsecuencia. Con este flujo, la llamada de atención pasa de O(N·S·d) a O(S²·d).
A diferencia de métodos previos como NSA, HISA, DSA o MoBA-que comprimen solo K y V y trasladan la lógica de selección a kernels personalizados — Lighthouse comprime Q, K y V de forma simétrica y coloca la selección fuera del kernel de atención. Esa decisión permite reutilizar kernels densos optimizados por hardware (por ejemplo FlashAttention), aprovechando implementaciones ya eficientes y evitando kernels especializados para selección.
FlashAttention ya reduce el footprint de memoria pero no cambia el escalado Θ(N²) del cómputo; Lighthouse aborda específicamente el cuello de botella durante el preentrenamiento de secuencias largas. Los autores han publicado los detalles técnicos para revisión y reproducibilidad en arXiv (arXiv:2605.06554).
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.