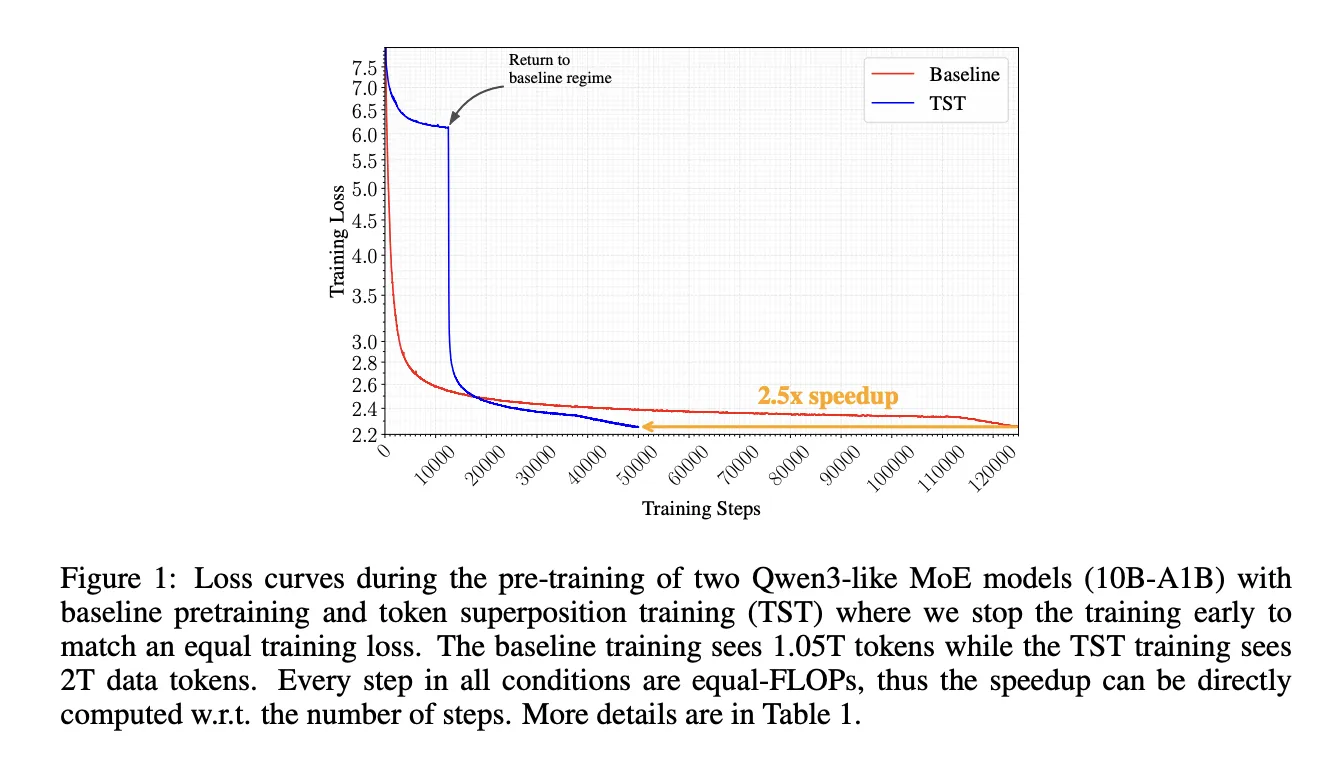
Nous Research anunció Token Superposition Training (TST), un esquema de preentrenamiento en dos fases diseñado para procesar más texto por unidad de cómputo y así reducir el tiempo y coste del preentrenamiento de LLM. El método promete acelerar el reloj de entrenamiento hasta 2.5× sin aumentar los FLOPs por paso, lo que lo hace atractivo para equipos que buscan menor duración de entrenamiento sin cambiar la inferencia.
Los autores validaron TST en modelos de 270M, 600M, 3B (densos) y 10B A1B MoE; el trabajo está disponible en arXiv:2605.06546. En la escala 10B A1B MoE, TST alcanzó una pérdida final inferior a la de la línea base emparejada por FLOPs, consumiendo 4,768 B200 GPU‑h frente a 12,311 B200 GPU‑h del baseline, una reducción aproximada de 2.5× en tiempo de preentrenamiento.
TST divide el preentrenamiento en dos fases. Fase 1 — Superposición: la secuencia se segmenta en bolsas de s tokens contiguos y se promedian sus embeddings para crear posiciones latentes de longitud L/s; la salida predice la siguiente bolsa usando una pérdida multi‑hot cross‑entropy (MCE) que reparte masa 1/s entre los s objetivos. Fase 2 — Recuperación: el entrenamiento vuelve a la predicción estándar token a token. El estudio identifica r ∈ [0.2,0.4] como fracción óptima de pasos en Fase 1.
Desde el punto de vista técnico, TST mantiene constantes el tokenizer, la arquitectura, el optimizador y la estrategia de paralelismo, y conserva los mismos FLOPs por paso al mostrar más longitud de datos durante la superposición. La MCE se implementa como la media de términos de cross‑entropy, aprovechando kernels CE ya presentes en bibliotecas de preentrenamiento, lo que facilita la integración.
Las consecuencias prácticas son directas: reducción de tiempo y gasto de preentrenamiento sin alterar el comportamiento de inferencia ni exigir nuevos heads o kernels, lo que facilita su adopción en pipelines existentes. El documento en arXiv contiene los detalles experimentales y los parámetros usados para reproducir los resultados.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.