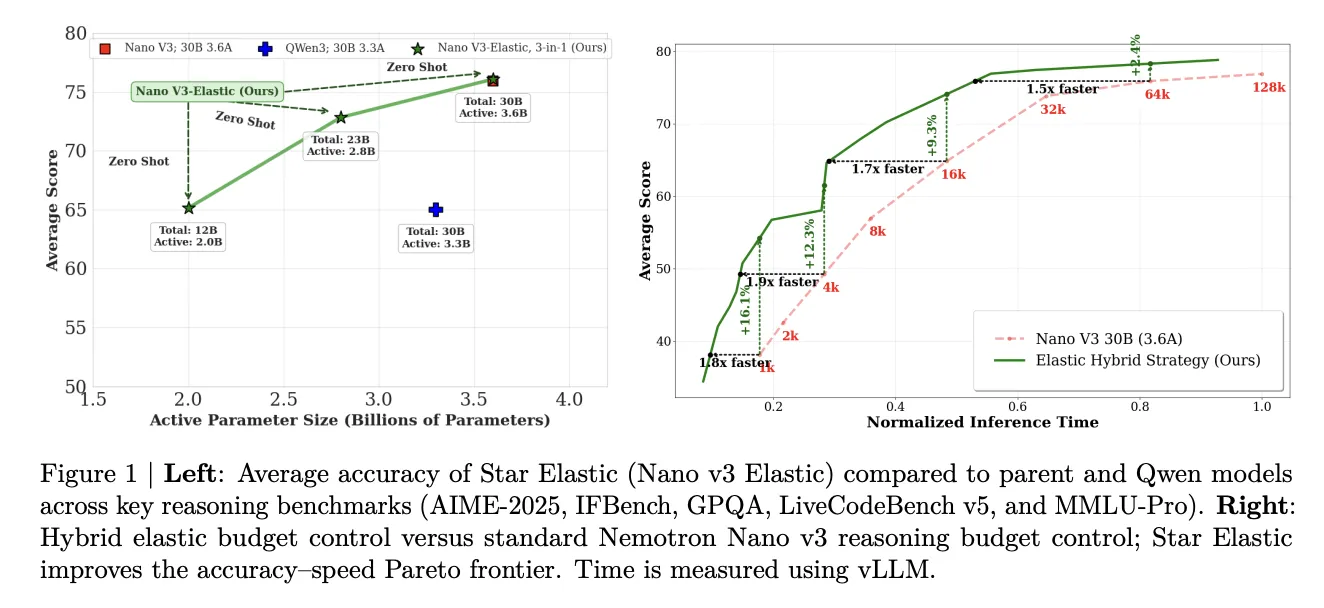
Star Elastic permite empaquetar variantes anidadas (30B, 23B, 12B) de Nemotron Nano v3 en un solo checkpoint entrenado en ~160B tokens, usando nested weight‑sharing, REAP y un enrutador con Gumbel‑Softmax;
NVIDIA presentó Star Elastic, una técnica de posentrenamiento que almacena varias variantes de razonamiento dentro de un único checkpoint aplicado a Nemotron Nano v3, y que permite extraer versiones menores sin fine‑tuning adicional. El equipo entrenó las variantes en una sola corrida de aproximadamente 160B tokens, lo que reduce el número de entrenamientos independientes necesarios para ofrecer tallas múltiples de modelo.
Nemotron Nano v3, al que se aplicó Star Elastic, es un híbrido Mamba — Transformer–MoE con 30B parámetros totales y 3.6B parámetros activos en su configuración completa. Star Elastic crea además variantes anidadas de 23B (2.8B activos) y 12B (2.0B activos) mediante un esquema de nested weight‑sharing que hace que las subversiones usen subconjuntos contiguos de componentes del modelo.
La técnica puntúa y selecciona componentes (canales de embedding, cabezas de atención, Mamba SSM, expertos MoE y FFN) usando importance estimation, y admite anidamiento en múltiples ejes: SSM, canales de embedding, cabezas de atención, número de expertos MoE y dimensión intermedia de FFN. Para ordenar expertos emplea REAP (Router‑Weighted Expert Activation Pruning), que basa el ranking en las puertas de ruteo y la magnitud de la salida.
A diferencia de compresiones fijas como Minitron, Star Elastic integra un enrutador aprendible que recibe un presupuesto objetivo (one‑hot) y genera máscaras diferenciables mediante Gumbel‑Softmax, permitiendo máscaras suaves durante el entrenamiento y corte eficiente para la inferencia. Este enrutador aprendible facilita el «slicing» cero‑shot de submodelos sin pasos adicionales de ajuste. En términos operativos, Star Elastic apunta a simplificar la gestión de variantes: reduce corridas de entrenamiento, almacenamiento y complejidad en la pila de despliegue; NVIDIA informa una reducción equivalente de aproximadamente 360× en tokens frente a entrenar cada modelo desde cero.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.