Parallax, desarrollada por equipos de Northwestern University, Tilde Research y University of Washington en colaboración de diseño con Muon, propone una variante parametrizada de Local Linear Attention (LLA) pensada para escalar el preentrenamiento de grandes modelos de lenguaje. Mantiene la atención softmax clásica y agrega una rama correctora de covarianza aprendida, un cambio que busca resolver cuellos de botella prácticos de LLA sin renunciar a su estructura estadística esencial. Esto afecta directamente la eficiencia de preentrenamiento y la implementación en aceleradores modernos.
En términos técnicos, Parallax reinterpreta la salida de atención como la suma de la atención softmax y una corrección aditiva que depende de la covarianza entre K y V. Esa corrección se aplica mediante un proyector aprendido ρ_i = W_R x_i, de modo que la salida final equivale a la salida softmax menos el término de covarianza proyectado por ρ_i. Además, el equipo fija a cero el factor denominado boundary amplification cuando el proyector es paramétrico para preservar la estabilidad numérica.
Frente a enfoques que intentan sustituir la atención softmax para ahorrar cómputo, Parallax introduce cómputo adicional pero optimizado para hardware contemporáneo. No pretende reducir la complejidad teórica del estimador local lineal; en lugar de resolver linealmente por consulta, reemplaza ese paso por una proyección entrenable que explora la covarianza KV a partir de la entrada de la capa (W_R). El resultado es una implementación más simple que conserva la esencia de LLA sin recurrir al solver por consulta costoso en I/O.
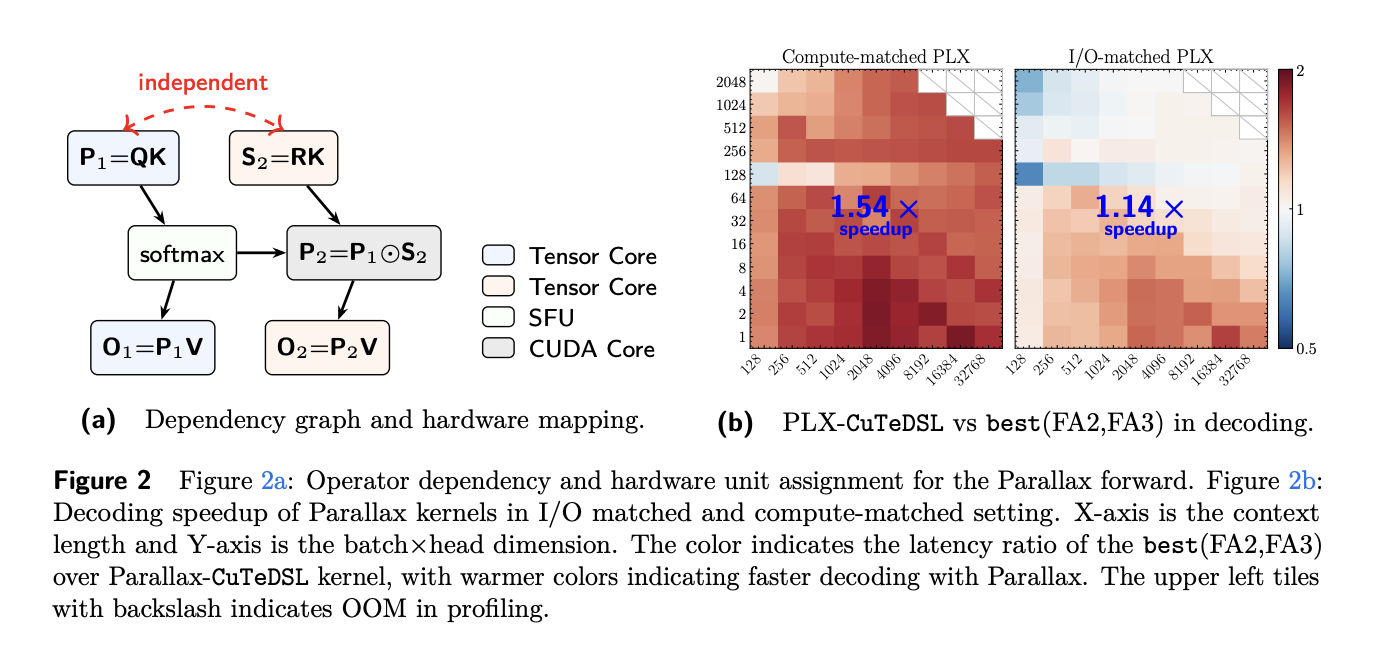
Desde la perspectiva de infraestructura, Parallax preserva la estructura de streaming empleada por FlashAttention y reutiliza el mismo flujo de claves y valores (K y V) para la rama de covarianza. Esa reorganización incrementa la intensidad aritmética — la relación entre operaciones en punto flotante y tráfico a memoria—; en regímenes dominados por el trabajo sobre KV, los autores reportan que la intensidad puede llegar a duplicarse, desplazando la carga hacia un modo más bound por cómputo donde las optimizaciones de kernel son más efectivas.
Para validar el argumento de infraestructura, el equipo prototipó un kernel de decodificación en CuTeDSL y perfiló su rendimiento en GPUs NVIDIA Hopper, midiendo en H200 con precisión BF16. Barrido experimental incluyó batches desde 1 hasta 2.048 y longitudes de contexto entre 128 y 32.768, con comparaciones frente a FlashAttention 2 y 3. En métricas de calidad, el paper informa mejoras de perplexity en modelos de 0.6B y 1.7B tras aplicar Parallax.
Por qué importa y limitaciones: Parallax mitiga problemas prácticos de LLA-el solver por consulta exige I/O intensivo, impone un trade — off entre regularización y expresividad y muestra fragilidad a baja precisión — al sustituirlo por una proyección entrenable compatible con las instrucciones de matmul en tensor cores. Sin embargo, la interpretación geométrica original de LLA cambia cuando el proyector es paramétrico; esa alteración motiva la desactivación del factor de amplificación de fronteras para asegurar estabilidad.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.