Investigadores de NUS, MIT CSAIL, A*STAR y SMART proponen MEMO (Memory as a Model), una arquitectura modular que entrena un modelo de memoria separado (MEMORY) para internalizar conocimiento nuevo y lo consulta desde un LLM ejecutor congelado (EXECUTIVE)
Un equipo formado por investigadores de la National University of Singapore (NUS), MIT CSAIL, A*STAR y la Singapore — MIT Alliance for Research and Technology (SMART) presenta MEMO, un marco modular pensado para incorporar conocimientos nuevos en aplicaciones basadas en grandes modelos de lenguaje sin modificar los parámetros del modelo principal. El documento técnico está disponible en arXiv y describe tanto la arquitectura como la metodología experimental empleada.
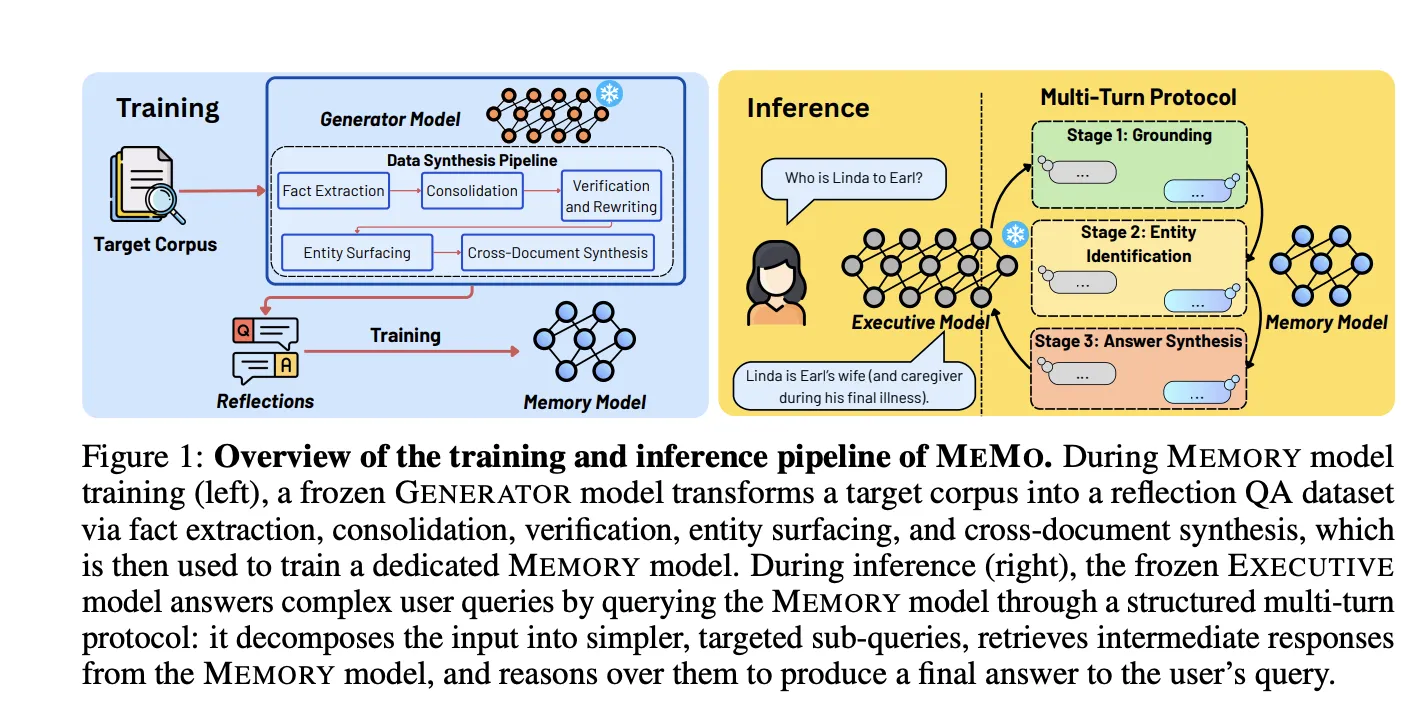
La propuesta separa explícitamente la función de memoria de la de razonamiento: el componente MEMORY es un modelo de lenguaje de tamaño reducido y entrenable que internaliza información de un corpus objetivo, mientras que el EXECUTIVE es el LLM principal, mantenido congelado y consultado a través de su interfaz I/O estándar. En los experimentos reportados, MEMORY se basó en Qwen2.5 — 14B-Instruct; los EXECUTIVE usados fueron Qwen2.5 — 32B-Instruct y Gemini — 3-Flash. MEMO opera sin acceso a pesos ni a logits del EXECUTIVE, tratándolo como una caja negra.
Para entrenar el MEMORY los autores desarrollaron una canalización de síntesis de datos en cinco pasos, guiada por un GENERATOR (en los experimentos, Qwen2.5 — 32B-Instruct): 1) extracción de hechos explícitos e inferidos del corpus objetivo; 2) consolidación de pares pregunta — respuesta (QA) agrupados por contexto común; 3) verificación y reescritura para garantizar que cada QA sea autocontenida; 4) 'entity surfacing' para mitigar errores de inversión de identidades; y 5) síntesis cross — documental que genera preguntas y respuestas que abarcan evidencia distribuida en múltiples documentos. una ablación 'leave — one-out' que la omitió redujo la puntuación en NarrativeQA de 24.00% a 6.37%.
El entrenamiento del MEMORY se realiza mediante fine-tuning supervisado (SFT) sobre los pares QA sintetizados, calculando la pérdida únicamente sobre los tokens de respuesta. Durante la inferencia no se entregan documentos fuente: el MEMORY debe responder usando el conocimiento paramétrico almacenado en sus pesos. Esa condición distingue a MEMO de soluciones que dependen de recuperación de documentos en cada consulta y que mantienen un acoplamiento directo con la base documental.
La interacción entre EXECUTIVE y MEMORY sigue un protocolo multi — turn estructurado en tres etapas. Primero, Grounding: el EXECUTIVE descompone la consulta en subpreguntas atómicas. Segundo, Identificación de entidad: se realizan consultas iterativas al MEMORY para reducir el conjunto de candidatos hasta apuntar una entidad condicionante. Tercero, Búsqueda y síntesis de respuesta: el MEMORY recupera hechos condicionados por la entidad identificada y produce fragmentos breves en lenguaje natural que el EXECUTIVE utiliza para sintetizar la respuesta final. Al devolver fragmentos cortos, el coste de recuperación no escala con el tamaño del corpus, a diferencia de enfoques basados en RAG.
Los autores evaluaron MEMO en tres benchmarks exigentes: BrowseComp — Plus (investigación profunda multi — hop), NarrativeQA (comprensión narrativa de libros y guiones) y MuSiQue (razonamiento de 2–4 saltos sobre párrafos de Wikipedia). Con Gemini — 3-Flash como EXECUTIVE, MEMO alcanzó 53.58% en NarrativeQA frente a 23.21% de HippoRAG2; obtuvo 60.20% en MuSiQue frente a 57.00% de HippoRAG2; y logró 66.67% en BrowseComp — Plus frente a 66.33% de HippoRAG2. Empleando Qwen2.5 — 32B-Instruct como EXECUTIVE, MEMO marcó 54.22% en BrowseComp — Plus y 48.30% en MuSiQue. Según los autores, cambiar al EXECUTIVE Gemini produjo mejoras de 12.45%, 26.73% y 11.90% en los tres benchmarks respectivamente.
Como comparativa, el baseline Cartridges, que requiere acceso white — box al EXECUTIVE, anotó 0.00% en BrowseComp — Plus y 3.75% en NarrativeQA. Además, los investigadores probaron la robustez frente a ruido de recuperación añadiendo un documento distractor por cada documento de evidencia en BrowseComp — Plus: NV — Embed-V2 y HippoRAG2 sufrieron caídas de hasta 6.22%, mientras que la precisión de MEMO cambió en +0.55%, dentro de la desviación estándar reportada. Estas observaciones sugieren que internalizar conocimiento en un MEMORY entrenado reduce la sensibilidad al ruido frente a métodos no paramétricos dependientes de recuperación.
La importancia práctica de MEMO radica en ofrecer una vía para actualizar conocimiento sin retrenar un LLM a gran escala ni exponerlo al riesgo de 'catastrophic forgetting' que puede acompañar el fine-tuning del modelo principal. Al diseñar la memoria como un módulo separado y tratable como caja negra, el enfoque facilita su uso con modelos propietarios cerrados y permite que la MEMORIA permanezca estable al cambiar de EXECUTIVE. Los autores remiten al documento en arXiv para detalles adicionales sobre arquitectura, canalización de datos y evaluaciones complementarias.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.