Un artículo técnico de Marwan Sarieddine, publicado el 14 de mayo de 2026, plantea que la baja utilización de GPUs en pipelines multimodales suele deberse al preprocesamiento intensivo en CPU y propone la transmisión desagregada — implementada en Ray Data—:
El 14 de mayo de 2026, Marwan Sarieddine publicó un análisis técnico sobre el diseño de pipelines de datos para conjuntos multimodales a gran escala y propuso la estrategia de transmisión desagregada (disaggregated streaming) como solución operativa. El autor identifica un problema recurrente en producción: aunque los modelos en GPU son rápidos, las flotas terminan con GPUs infrautilizadas porque el pipeline upstream no las alimenta de forma sostenida.
Sarieddine documenta que en entornos reales la utilización de GPU a menudo cae por debajo del 50% y que esa pérdida no se debe tanto a la velocidad del modelo como a los cuellos de botella en el preprocesamiento. Las cargas multimodales — que combinan video, nubes de puntos, audio y texto — agravan la situación porque requieren transformaciones costosas en CPU antes de que la GPU pueda entrenar o inferir. El autor enumera operaciones concretas que son CPU‑bound y consumen buena parte del tiempo de época: decodificar video H.264, voxelizar nubes LIDAR, ejecutar OCR, tokenizar texto y aplicar aumentaciones de datos. Según el análisis, estas tareas pueden representar hasta el 65% del tiempo de una época en cargas multimodales, lo que deja a la GPU esperando lotes listos y reduce la eficiencia global.
Otro punto técnico importante es que las GPUs requieren workers stateful de larga duración para mantener pesos en memoria entre lotes; mantener esos procesos ocupados exige un flujo continuo de entradas preprocesadas. Cuando la preparación de datos se retrasa o se realiza en la misma instancia que la GPU pero sin capacidad de CPU suficiente, la GPU entra en idleness y la inversión en aceleradores no rinde.
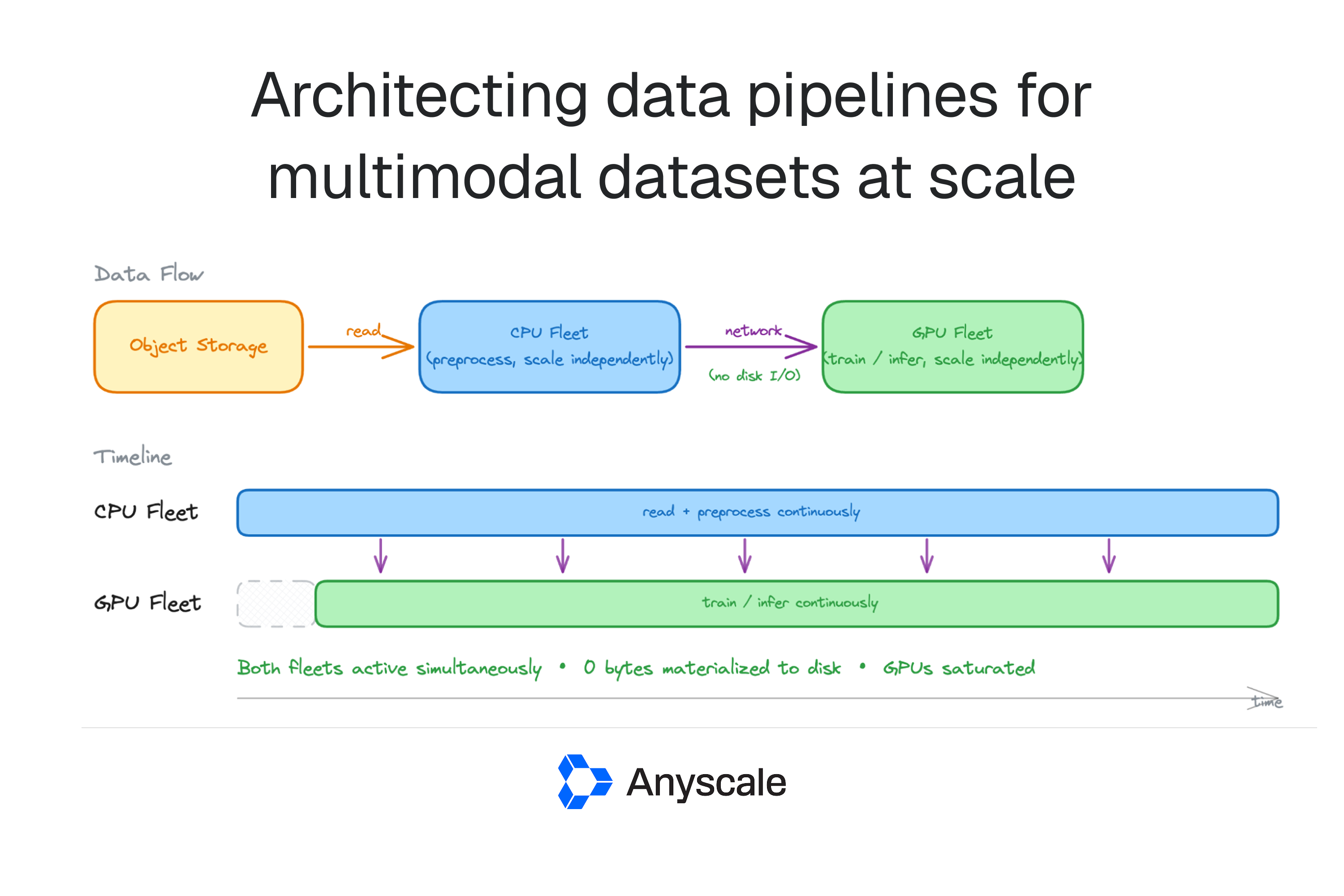
Como alternativa a los patrones tradicionales (procesamiento por lotes con intermedios en disco o ejecución en nodo único), el artículo describe la arquitectura de streaming desagregado: un conjunto dedicado de nodos CPU realiza preprocesamiento y transmite los resultados directamente a los workers GPU por la red, evitando la escritura de intermedios a almacenamiento persistente. El autor señala que Ray Data implementa este modelo y que el flujo típico es: almacenamiento de objetos → preprocesamiento en CPU → entrenamiento o inferencia en GPU, con intermediarios retenidos en buffers en memoria.
Para ilustrar el coste de los intermedios en disco, el texto ofrece un ejemplo numérico: partiendo de 500 TB de datos crudos que se expanden 2× hasta 1 PB de intermedios, las operaciones de I/O estimadas son leer 500 TB ≈ 1.5 horas; escribir 1 PB ≈ 3 horas; y leer 1 PB por la flota GPU ≈ 12 horas, lo que suma aproximadamente 16.5 horas de I/O durante las cuales CPUs o GPUs permanecen inactivas. Ese cálculo muestra cómo la serialización a almacenamiento puede introducir ventanas largas de inactividad y afectar el tiempo total de entrenamiento.
El artículo también examina por qué la ejecución en nodo único resulta subóptima para cargas multimodales intensivas en CPU: las instancias optimizadas para densidad de GPU no ofrecen proporciones de vCPU suficientes. Cita ejemplos concretos de instancias: p4d.24xlarge dispone de 96 vCPU y 8× A100 (equivalente a 12 vCPU por GPU), mientras que p5.48xlarge ofrece 192 vCPU y 8× H100 (24 vCPU por GPU). Para preprocesamiento multimodal intensivo, esas relaciones CPU/GPU suelen ser insuficientes.
Como caso práctico, el autor menciona un experimento con un workload de Vision Transformer que procesa alrededor de 4 TiB: suplementar 40 nodos GPU con 64 nodos CPU dedicados produjo un incremento de throughput de 7× frente a Daft, cuyo paso queda limitado por la capacidad de CPU que las instancias GPU proporcionan. Esa observación sirve para subrayar la ganancia práctica que puede obtenerse al separar flotas por función — CPU para preparación, GPU para cálculo — en lugar de forzar ambos roles en la misma máquina.
Según el análisis, la transmisión desagregada aporta tres ventajas operativas clave: evita materializar intermedios en disco y las largas ventanas de I/O asociadas; permite escalar CPU y GPU de forma independiente según la demanda de cada etapa; y habilita la ejecución solapada (mientras la GPU procesa el lote N, la CPU prepara el N+1). En conjunto, estos efectos pueden elevar la utilización de GPU y mejorar la relación coste‑rendimiento en entrenamientos e inferencia multimodal.
El autor reconoce también las limitaciones y compensaciones del enfoque: los intermedios en disco tienen valor para inspección, depuración y reproducibilidad, y cuando las transformaciones cambian entre épocas (por ejemplo, aumentaciones dependientes de la época) esos intermedios no son reutilizables y el coste de I/O se paga igualmente. En consecuencia, equipos y arquitectos deben evaluar trade‑offs entre reproducibilidad, coste de almacenamiento y latencia operativa al elegir entre materializar intermedios o adoptar transmisión en memoria.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.