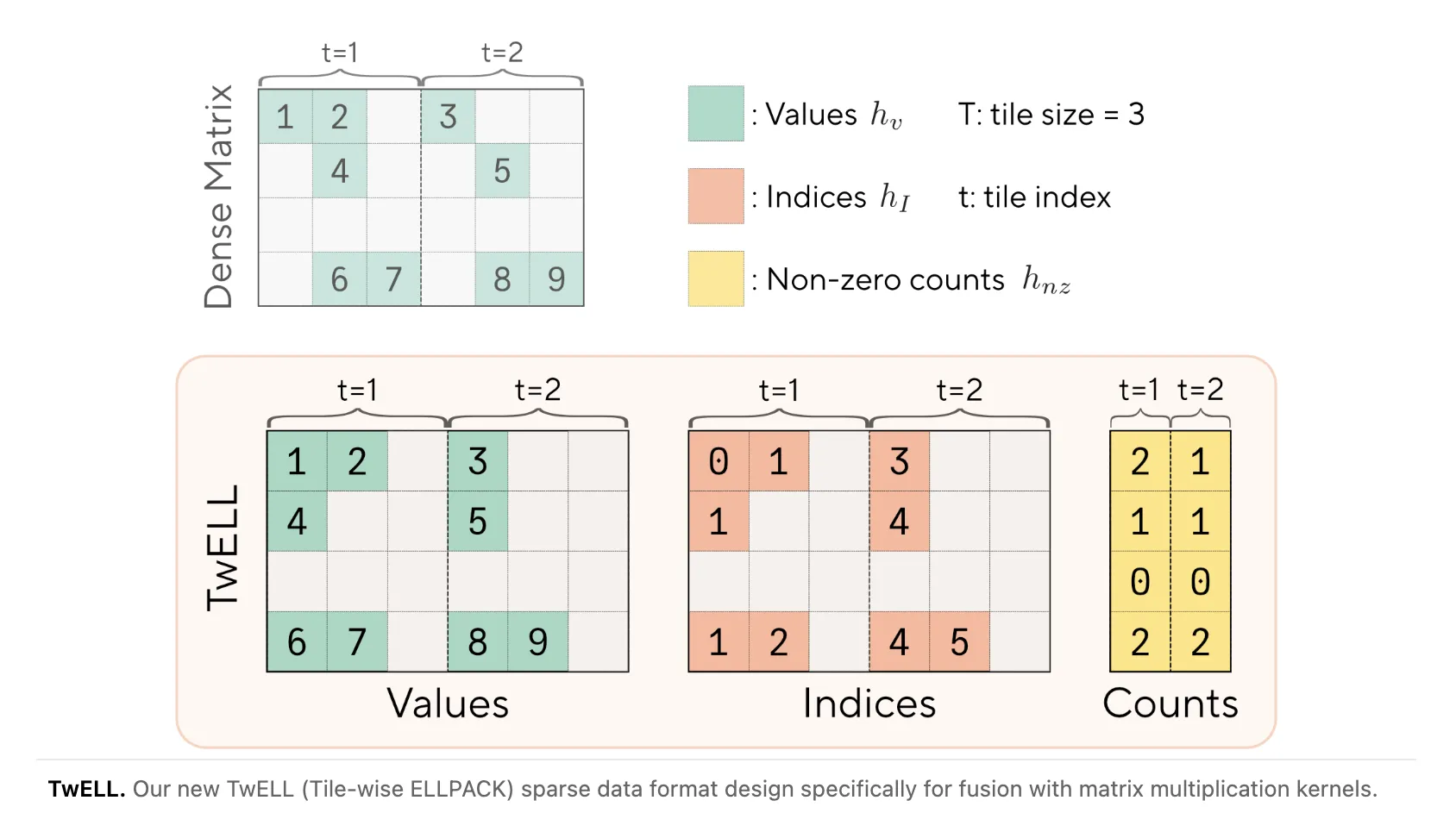
Sakana IA y NVIDIA presentaron TwELL, un conjunto de técnicas y kernels CUDA que explotan la sparsidad de activaciones en las capas feedforward de transformadores para recortar coste computacional. Los autores informan que aplicando regularización L1 pueden inducir más del 99% de sparsidad en esas activaciones con un impacto insignificante en el rendimiento del modelo, y que las mediciones en GPU muestran mejoras reales: 20.5% en inferencia y 21.9% en entrenamiento.
TwELL no modifica la arquitectura del modelo sino que reduce el trabajo dentro de las capas feedforward aprovechando que muchas neuronas no se activan para un token dado. Para convertir esa sparsidad en aceleración práctica se proponen nuevos formatos de datos dispersos y kernels CUDA fusionados, diseñados específicamente para mantener rendimiento en operaciones por lote tanto en entrenamiento como en inferencia.
A diferencia de enfoques anteriores orientados a GEMV de token único (TurboSparse, ProSparse, Q‑Sparse), el equipo busca ganancias en GEMM por lotes, el modo en que las GPUs modernas emplean Tensor Cores y operaciones densas en tiles grandes. Ese enfoque por lotes es clave para traducir la sparsidad teórica en aceleración real en escenarios de alto rendimiento donde se procesan muchos tokens juntos.
El trabajo se centra en un cuello de botella estructural: las capas feedforward representan más de dos tercios de los parámetros y consumen más del 80% de los FLOPs en modelos grandes, además de producir numerosas activaciones que quedan a cero tras la función de activación. Optimizar específicamente estas capas puede, por tanto, impactar de forma significativa el coste computacional en modelos de gran escala.
Los autores publican el estudio en arXiv (2603.23198) y lo vinculan a ICML 2026. Si las técnicas y los kernels se adoptan a escala, podrían reducir el coste de entrenamiento e inferencia de LLMs en entornos que usan lotes grandes y buscan optimización de throughput, aunque la transición a producción exigirá integración con stacks existentes y pruebas adicionales de robustez.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.