StepFun, laboratorio de IA con sede en Shanghái, lanzó en mayo de 2026 StepAudio 2.5 Realtime, un modelo de voz end-to-end que procesa audio de entrada a salida en tiempo real y permite personalizar por completo la persona del hablante. El sistema admite chino e inglés, hereda capacidades TTS previas para ajustar tono global y matices intra‑frase, y se conecta mediante una API WebSocket en wss://api.stepfun.com/v1/realtime usando el identificador de modelo step-2.5 — realtime.
Este enfoque unificado evita la separación clásica por pipelines (reconocimiento, razonamiento y síntesis) y promete respuestas más coherentes en aplicaciones conversacionales. StepFun describe tres pilares técnicos que sustentan el modelo. Primero, una expansión algorítmica de datos de persona que parte de más de 10,000 muestras nativas y las transforma en una matriz de características a escala de millones, combinada con millones de conversaciones reales para enriquecer el entrenamiento. Segundo, entrenamiento con RLHF (Reinforcement Learning from Human Feedback) específicamente orientado a roleplay para mantener la consistencia de la persona.
Tercero, una fusión de comprensión y generación de voz mediante aprendizaje por refuerzo que integra interpretación y síntesis en un solo proceso.
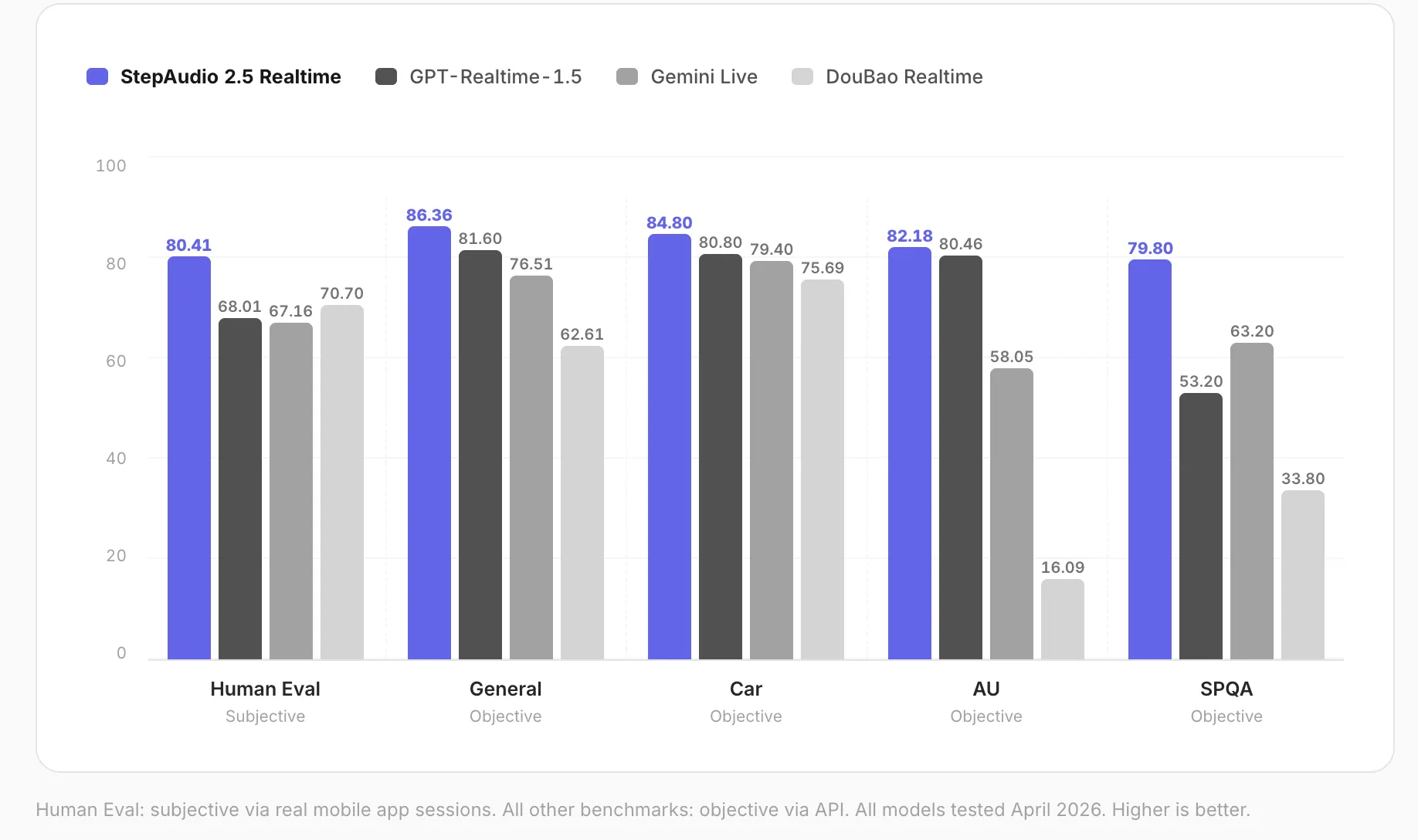
En pruebas internas de abril de 2026, StepAudio 2.5 Realtime obtuvo el primer puesto en las cinco dimensiones evaluadas, con una puntuación de 80.41 en evaluación humana y 82.18 en comprensión paralingüística. Según StepFun, la combinación de RLHF orientado a roleplay y la ampliación de datos de persona busca reducir desviaciones fuera de personaje y mejorar la sensibilidad emocional del sistema al interpretar señales no verbales — como variaciones de tono, ritmo, pausas, suspiros o risa-que pueden indicar fatiga o frustración.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.