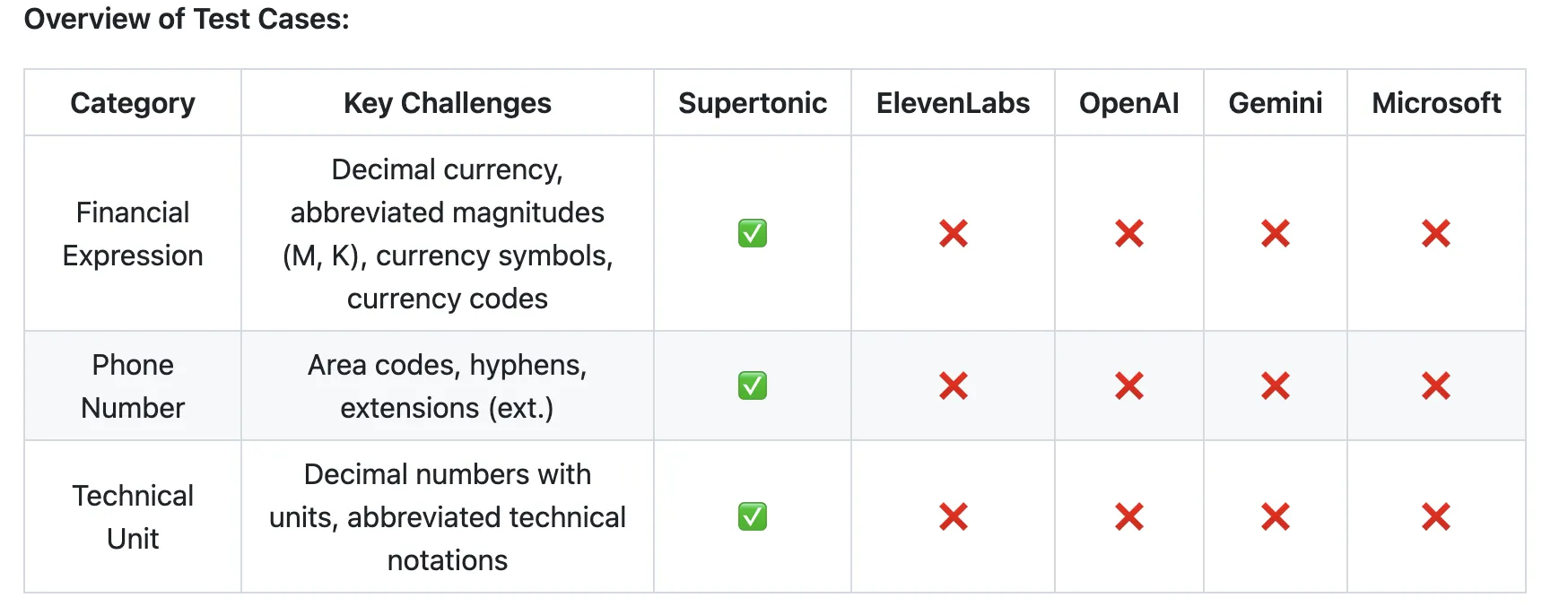
Supertone presentó Supertonic 3 el 15 de mayo de 2026, la tercera generación de su sistema de síntesis de voz on‑device en formato ONNX. La actualización reduce la tasa de fallos de lectura — repeticiones y omisiones— e introduce etiquetas expresivas para marcar señales prosódicas en el texto sin alterar el contrato de inferencia de las integraciones ya desplegadas. Esto permite a clientes e integradores adoptar las mejoras sin necesidad de reescribir los puntos de inferencia.
La cobertura de idiomas se amplía de 5 a 31 códigos ISO: la versión anterior soportaba inglés, coreano, español, portugués y francés; Supertonic 3 añade japonés, árabe, búlgaro, checo, danés, alemán, griego, estonio, finlandés, croata, húngaro, indonesio, italiano, lituano, letón, holandés, polaco, rumano, ruso, eslovaco, esloveno, sueco, turco, ucraniano y vietnamita. Además incorpora un fallback "na" para textos fuera del conjunto. El paquete público contiene aproximadamente 99 millones de parámetros y ocupa 404 MB en disco.
En cuanto a arquitectura, Supertonic 3 conserva un autoencoder de voz y un predictor de duración, y reemplaza el tradicional text‑to‑audio directo por un módulo text‑to‑latent basado en flow‑matching. El uso de flow‑matching reduce el coste de muestreo frente a modelos de difusión, lo que permite generar salida utilizable en apenas dos pasos de inferencia.
La versión también integra técnicas de alineación y robustez: LARoPE para mejorar la correspondencia texto‑voz y una técnica denominada Self‑Purifying Flow Matching para hacer el modelo más resistente a datos ruidosos. Frente a sistemas TTS abiertos de mayor tamaño (entre 0,7 y 2 mil millones de parámetros), Supertonic 3 es considerablemente más pequeño, lo que facilita descargas e inferencia local.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.