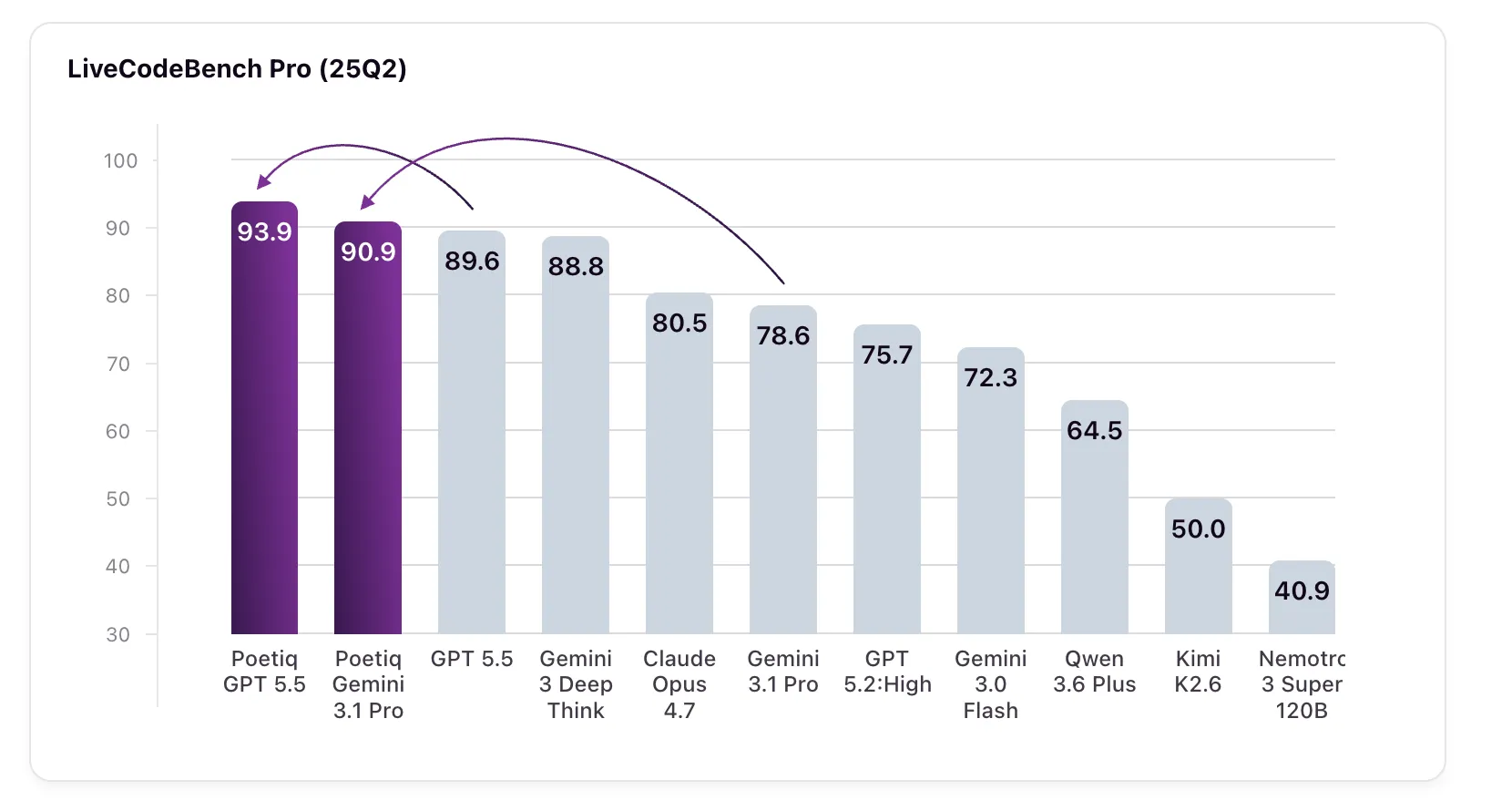
Poetiq publicó resultados en los que su Meta‑System generó y ajustó automáticamente un arnés de inferencia para LiveCodeBench Pro (LCB Pro) y, según la compañía, mejoró el desempeño de todos los modelos probados sin emplear fine‑tuning ni acceder a los internals de los modelos. Esto importa porque sugiere que la ingeniería de inferencia, en lugar del entrenamiento adicional, podría elevar la eficacia de LLM en tareas de programación.
Los números citados en el informe muestran ganancias significativas: GPT 5.5 High con el arnés alcanzó 93.9% en LCB Pro (25Q2), desde una línea base de 89.6%. Gemini 3.1 Pro pasó de 78.6% a 90.9%, superando a Gemini 3 Deep Think (88.8%), que, según Poetiq, no está disponible por API para verificación externa. El informe presenta estos resultados como evidencia de la eficacia del arnés, pero la ausencia de acceso a algunos modelos limita la verificación independiente.
LiveCodeBench Pro es un benchmark de programación competitiva que extrae problemas de competencias reales, conserva el código de verdad público y valida soluciones mediante un marco de pruebas que aplica límites de memoria y tiempo. Se centra en desafíos en C++ organizados por dificultad y se actualiza de forma continua; Poetiq lo seleccionó por su resistencia a la contaminación de datos y al sobreajuste, lo que refuerza la relevancia práctica de los resultados reportados.
Poetiq plantea tres objetivos cumplidos: demostrar que un arnés inteligente puede elevar la eficacia sin fine‑tuning ni acceso especial, validar la capacidad de auto‑mejora recursiva de su Meta‑System y mostrar que el arnés es agnóstico al modelo. Poetiq.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.