Zyphra anunció Tensor and Sequence Parallelism (TSP), una estrategia de paralelismo orientada al hardware diseñada para entrenamiento e inferencia de grandes modelos transformer con contextos extensos. La compañía describe TSP como un enfoque para disminuir simultáneamente la memoria de parámetros y la de activaciones por dispositivo, y presenta resultados que van desde pruebas en un único nodo de 8 GPUs MI300X hasta evaluaciones a escala en 128 nodos (1,024 GPUs).
El núcleo técnico de TSP es lo que Zyphra denomina "plegado de paralelismo": en lugar de organizar Tensor Parallelism (TP) y Sequence Parallelism (SP) en ejes ortogonales de una malla de dispositivos, ambos tipos de paralelismo se colapsan en un único eje de tamaño D. Bajo este esquema, cada GPU almacena 1/D de los pesos del modelo y procesa 1/D de la secuencia de tokens, de modo que la memoria tanto de modelo como de activaciones en ese eje disminuye de forma proporcional al factor 1/D.
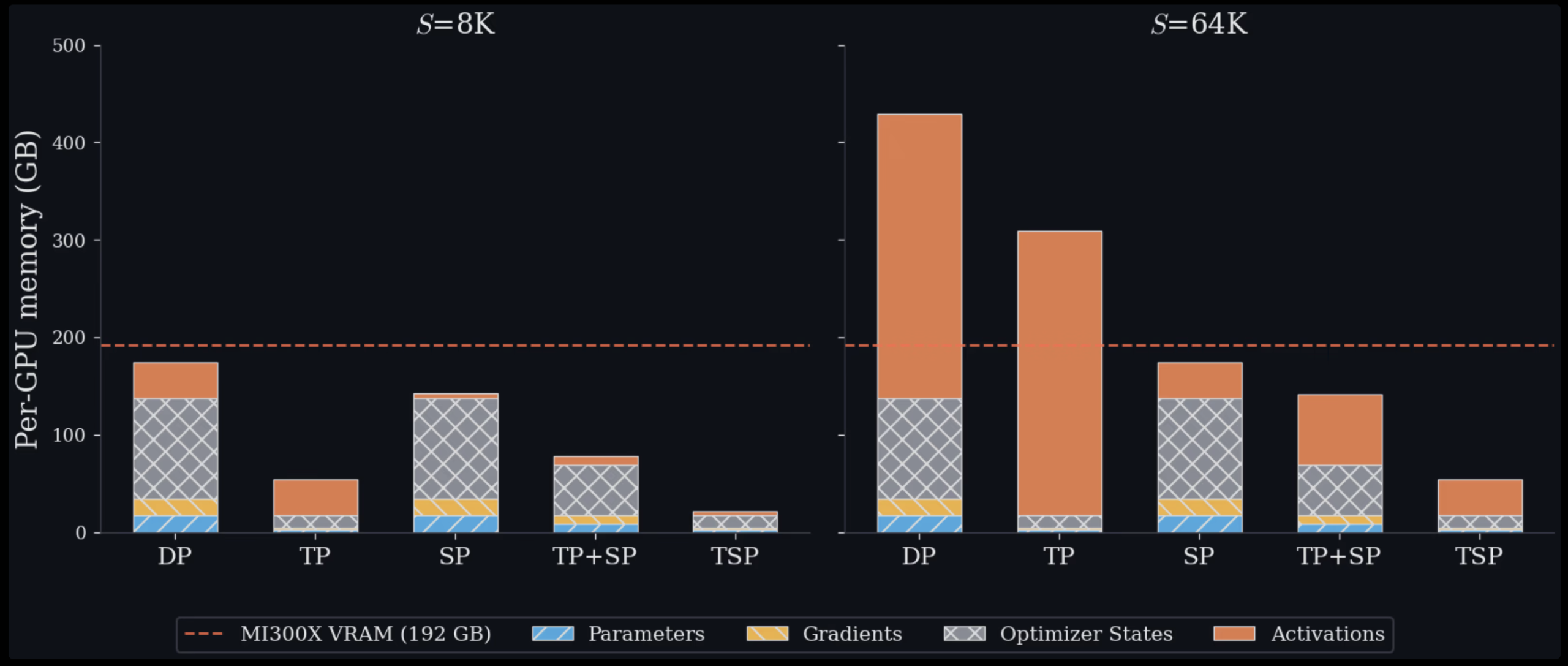
Ese plegado plantea una alternativa a las configuraciones convencionales. Hoy se emplean TP (que reparte pesos) y SP (que reparte tokens) de forma separada o combinada en mallas bidimensionales; TP reduce la memoria de parámetros pero impone comunicaciones colectivas cuyo coste aumenta con las activaciones, mientras que SP reduce la memoria de activaciones a costa de replicar pesos en cada GPU. La factorización habitual TP+SP puede consumir T·Σ GPUs y generar comunicaciones entre nodos cuando la factorización cruza límites físicos. TSP busca evitar esa ampliación dimensional y sus implicaciones comunicacionales al plegar ambos paralelismos en un solo eje.
La implementación de la capa de atención en TSP se organiza en iteraciones sobre fragmentos (shards) de pesos. En cada paso, una GPU hace broadcast de sus shards empaquetados de WQ, WK, WV y WO al resto del grupo; cada dispositivo aplica esas matrices locales sobre su porción de tokens para producir Q, K y V locales. Dado que la atención causal requiere claves y valores completos, las K y V locales se reúnen mediante all-gather entre el grupo y se reordenan con un esquema de partición denominado "zigzag" antes de aplicar FlashAttention, lo que contribuye a balancear la carga por rango.
Para las MLP con compuerta (gating), TSP emplea un calendario en anillo. Cada GPU comienza con shards locales de las proyecciones gate, up y down; esos shards circulan por el grupo usando send/recv punto a punto mientras cada GPU acumula salidas parciales a medida que llegan. Ese diseño evita el all-reduce que TP suele necesitar para la salida de la MLP y está concebido para solapar las transferencias de pesos con las operaciones GEMM computacionales, reduciendo latencias y comunicaciones colectivas en ese bloque.
Zyphra reporta cifras concretas de memoria y rendimiento. En un nodo de 8 GPUs MI300X, TSP mostró el menor pico de memoria en pruebas con longitudes de secuencia entre 16K y 128K tokens: a 16K, TSP alcanzó 31.0 GB por GPU frente a 31.5 GB con TP; a 128K, TSP consumió 38.8 GB por GPU frente a 70.0 GB con TP. Además, dos factorizaciones TP+SP evaluadas en el mismo escenario usaron 85.0 GB y 140.0 GB por GPU, respectivamente.
En escalado a 128 nodos (1,024 MI300X), con grado de plegado D=8 y secuencia de 128K tokens, TSP alcanzó 173 millones de tokens/s, en comparación con 66.30 millones de tokens/s para el baseline TP+SP emparejado. Estos resultados indican una mejora sustancial de throughput en cargas de muy largo contexto al aplicar el plegado de ambos paralelismos sobre un solo eje.
Zyphra aclara que muchas de las cifras y análisis provienen de un modelo de referencia denso de 7B para decodificador (h=4096, 32 capas, 32 cabezas de query, 32 cabezas KV, factor de expansión FFN F=4, precisión bf16). La compañía presentó los detalles de los calendarios de comunicación y los esquemas de partición; los ensayos cubren tanto entrenamiento como serving y los resultados se exponen en la documentación técnica enlazada por la compañía.
Las implicaciones prácticas de TSP, según la descripción técnica, son reducir el consumo de VRAM por GPU y permitir procesar secuencias más largas o emplear modelos mayores con la misma infraestructura física. Al mismo tiempo, el método introduce patrones de comunicación distintos — broadcasts iterativos, all-gathers para K/V y circulación en anillo para MLP-que buscan minimizar colectivas costosas y solapar comunicaciones con cómputo, lo que puede traducirse en ventajas reales en despliegues a gran escala. Para quienes deseen reproducir o profundizar en los detalles, Zyphra publicó los calendarios de comunicación, los esquemas de partición y los resultados experimentales en su documentación técnica. Las cifras presentadas incluyen tanto estimaciones teóricas como mediciones empíricas sobre el hardware mencionado y abarcan tanto escenarios de entrenamiento como de serving.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.