Investigadores de Sakana IA y la Universidad de Tokio presentan DiffusionBlocks, un marco de entrenamiento por bloques que interpreta las actualizaciones residuales como pasos de denoising en un proceso de difusión inversa.
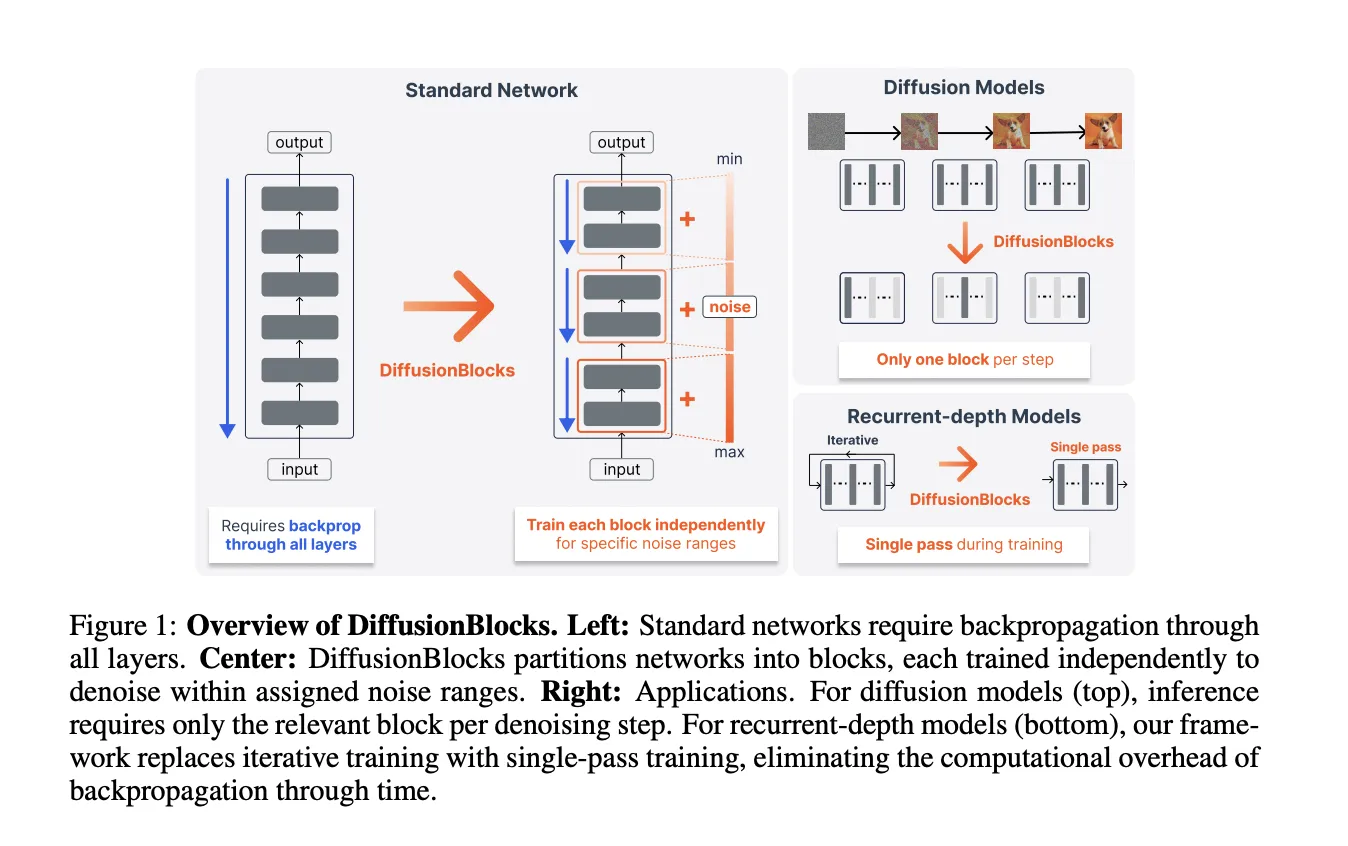
Qué ocurrió: Un equipo conjunto de Sakana IA y la Universidad de Tokio presentó DiffusionBlocks, un marco que permite entrenar redes profundas — incluyendo modelos tipo transformer — una porción (bloque) a la vez. Los autores informan que la memoria necesaria para entrenar se reduce aproximadamente en un factor B, donde B es el número de bloques en que se particiona la red, y que la precisión se conserva en arquitecturas diversas.
Detalles técnicos: La propuesta parte de interpretar la actualización residual z_l = z_{l-1} + f_{θ_l}(z_{l-1}) como una discretización de Euler del flujo de probabilidad inverso en modelos de difusión basados en score (formulación VE). Bajo esa equivalencia, cada bloque residual corresponde a un paso de denoising en un intervalo de niveles de ruido, y el objetivo de score matching puede optimizarse localmente en cada nivel. Eso permite entrenar cada bloque de forma independiente sin intercambio continuo de activaciones entre bloques.
o competitivo y problema que aborda: El trabajo apunta al cuello de botella de memoria del retropropagación end-to-end, que exige almacenar activaciones en todas las capas y cuyo consumo crece linealmente con la profundidad. con Adam, cada capa requiere memoria para parámetros, gradientes y dos estados de optimizador, es decir, aproximadamente 4 veces el tamaño de los parámetros por capa. Métodos previos (Forward — Forward, entrenamiento greedy por capas) han sido ad hoc, con pérdida de rendimiento y limitados mayoritariamente a clasificación.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.