Stability IA presentó Stable Audio 3, una familia de modelos para generar y editar audio estéreo a 44.1 kHz, acompañada de un paper técnico y pesos abiertos para las variantes small y medium alojados en Hugging Face; la variante large queda disponible solo bajo licencia empresarial. El lanzamiento importa porque combina generación de larga duración y capacidades de inpainting con acceso abierto a modelos útiles para desarrolladores e investigadores.
La familia incluye tres escalas: small, medium y large. El modelo small es un transformer de difusión de 459 millones de parámetros, ofrece versiones orientadas a música y a efectos y admite salidas de hasta 2 minutos. El medium tiene 1.4 millardos de parámetros y puede generar hasta 6 minutos y 20 segundos; el large alcanza 2.7 millardos de parámetros con el mismo límite temporal que la medium. Todos los modelos operan sobre un autoencoder semántico‑acústico SAME para convertir y reconstruir audio en latentes compactos.
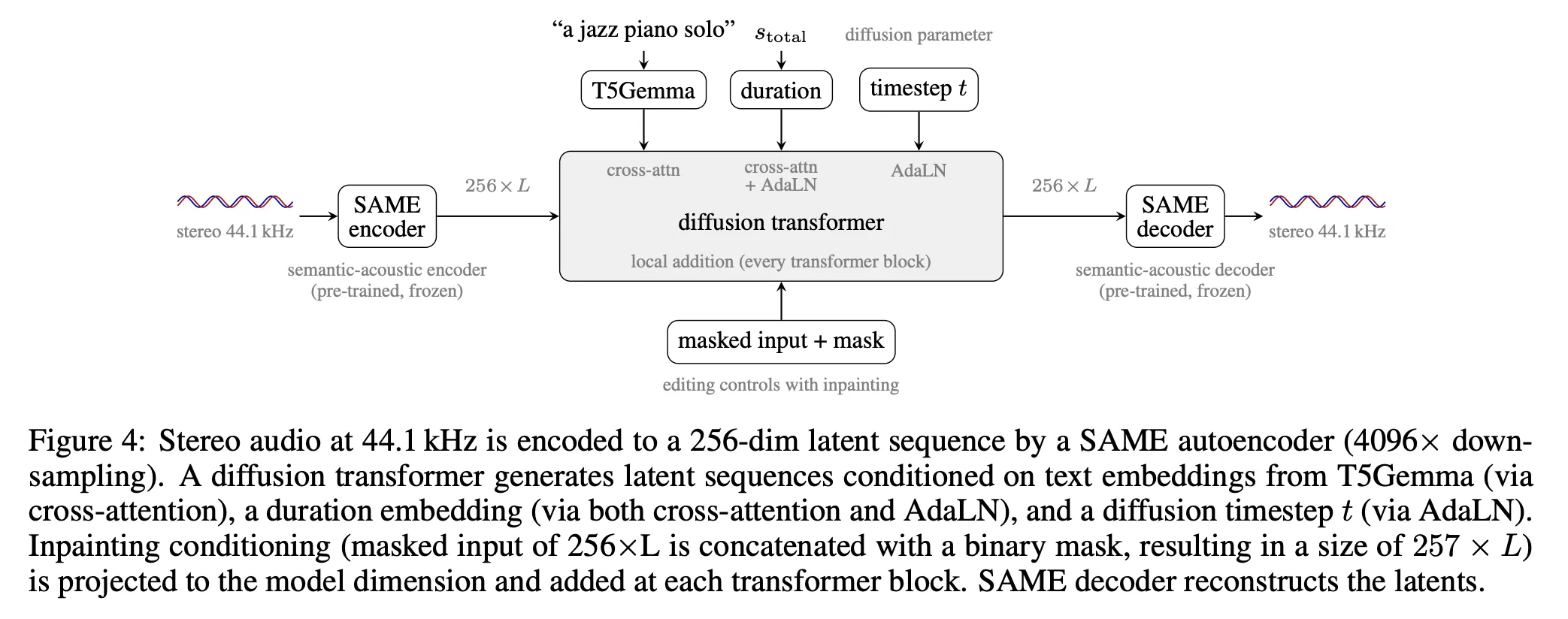
El sistema consta de dos componentes principales: el autoencoder SAME y un diffusion transformer condicionado por texto, duración y máscaras de inpainting. SAME se entrega en dos tamaños de autoencoder — SAME‑S (108M parámetros) y SAME‑L (852M)— y logra una compresión total de 4.096× mediante un parcheado inicial (256×) seguido de un Transformer Resampling Block que aplica un factor adicional de 16×. El proceso produce secuencias latentes de 256 dimensiones a aproximadamente 10,76 Hz, que alimentan el modelo de difusión para reconstruir audio a 44.1 kHz.
En términos de rendimiento y uso, Stable Audio 3 permite edición rápida y generación de larga duración en hardware de consumo: la variante small puede ejecutarse en un MacBook Pro M4 exclusivamente en CPU, mientras que la medium cabe en GPUs con 8 GB de VRAM. En evaluaciones, la medium alcanzó un FAD de 0.369 en 5 segundos en el benchmark BBC Sound Effects, cifra inferior a todos los baselines de pesos abiertos analizados en el documento, lo que sugiere un rendimiento competitivo en efectos de sonido.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.