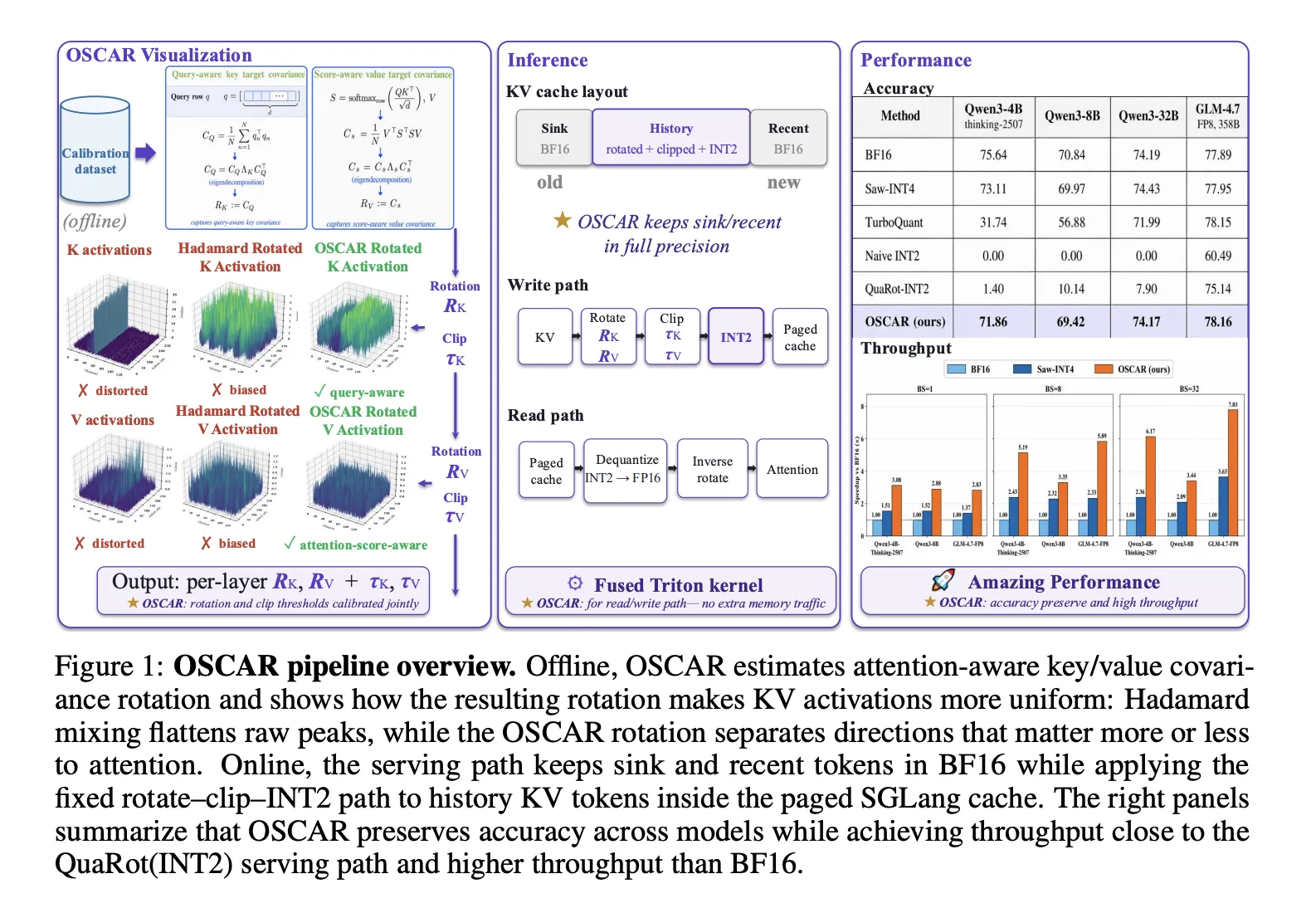
Together IA ha publicado OSCAR (Offline Spectral Covariance — Aware Rotation), un método de cuantización INT2 diseñado para reducir el uso de memoria y acelerar el servicio de modelos de lenguaje con contextos muy largos. El enfoque comprime directamente la caché de claves/valores (KV) durante la inferencia autoregresiva, lo que interesa especialmente a despliegues que manejan contextos de hasta 100 000 tokens porque puede reducir tráfico de memoria y permitir mayores tamaños de lote.
En las pruebas reportadas, OSCAR logra una tasa media de 2.28 bits por elemento KV y acorta la brecha de precisión frente a BF16 en 3.78 puntos para Qwen3 — 4B-Thinking-2507 y en 1.42 puntos para Qwen3 — 8B. Además, se observa aproximadamente una reducción de 8× en el uso de memoria de la caché KV y hasta 3× de aceleración en la decodificación cuando se evalúa con contextos de 100 000 tokens, cifras que ilustran el potencial operativo del método en entornos de producción.
La técnica funda su rotación previa a la cuantización en estadísticas de atención. Para claves, estima la covarianza de consultas CQ = (1/N) Σ qnᵀ qn y utiliza sus autovectores como base de rotación; para valores, define una covarianza ponderada por los scores de atención. Ese diseño busca orientar la compresión hacia subespacios menos relevantes para las consultas, minimizando el impacto de la cuantización en las operaciones de atención.
OSCAR aborda limitaciones de enfoques previos: la cuantización a INT2 resultaba impráctica porque unos pocos canales con valores atípicos dominaban la escala, y las rotaciones fijas (por ejemplo Hadamard) eran agnósticas a qué direcciones amplifican el error de atención. Al derivar la rotación de la estadística de atención y mantener compatibilidad con diseños de caché paginados, OSCAR pretende ofrecer un equilibrio operativo entre ahorro de memoria y precisión en modelos como Qwen3.
Fuentes
Respuestas (0)
Aún no hay respuestas en este tema.