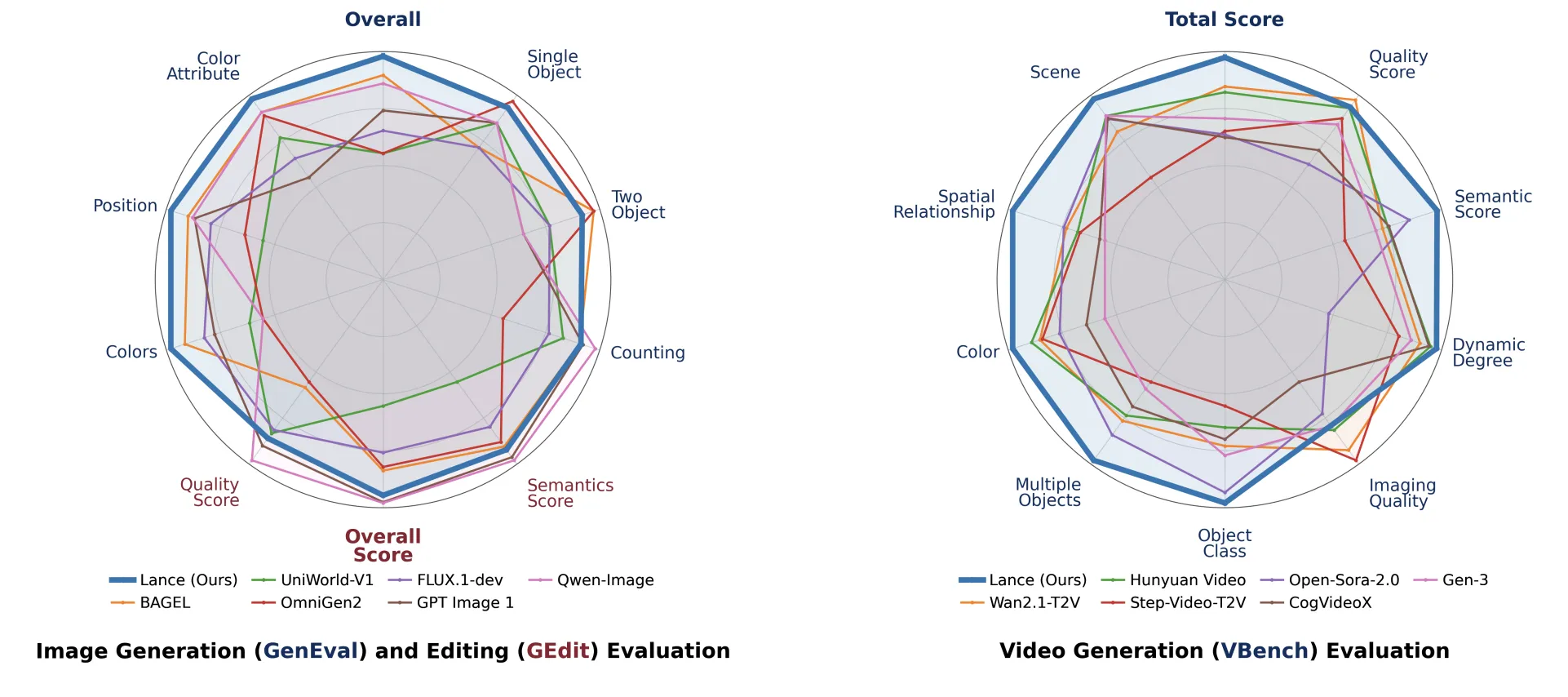
ByteDance выпустила Lance — открытый мультимодальный фреймворк с 3 млрд активированных параметров, который объединяет распознавание, генерацию и согласованное редактирование изображений и видео в одной архитектуре;
ByteDance объявила о выпуске Lance — открытого нативного мультимодального модельного фреймворка, который в единой архитектуре объединяет задачи понимания, генерации и редактирования для изображений и видео. Модель работает при трёх миллиардах активированных параметров и обучалась совместно; исходный текст с описанием и код доступны в сопроводительном релизе и на arXiv. Это важно для разработчиков и исследователей: единая система обещает упростить создание приложений, где требуются одновременно анализ визуального контента и его синтез или правка.
Функционально Lance организован в три выходные семейства: X2T для текстовых выходов, X2I для изображений и X2V для видео. В блоке «понимание» модель покрывает подпроцессы автогенерации подписей (captioning), визуального вопрос‑ответа (VQA), OCR, визуального граундинга и мультимодального рассуждения. В части генерации и редактирования поддерживаются тексты→изображение, тексты→видео, изображение→видео, subject‑driven generation и редактура как изображений, так и видео с возможностью многократного согласованного редактирования.
Архитектура опирается на объединённое контекстное моделирование при разъединённых путях возможностей. Все входы — текст, изображения и видео-конвертируются в единый чередующийся мультимодальный токен‑поток. Текстовые токены получают эмбеддинги от Qwen2.5‑VL; смысловые визуальные токены для задач понимания формируются ViT‑энкодером той же Qwen2.5‑VL. Для генеративной части визуальные входы кодируются 3D causal VAE Wan2.2 и преобразуются в непрерывные латенты; при этом VAE выполняет 16× пространственное и 4× временное даунсемплирование визуальных латентов. Над общей последовательностью применяется обобщённое 3D causal attention: текст использует причинное внимание, визуальные токены — двунаправленное, что позволяет совместно учитывать семантику и непрерывную структуру визуальных данных.
Для разделения задач Lance использует двухпоточный mixture‑of‑experts, инициализированный от Qwen2.5‑VL 3B. Эксперт понимания LLMUND обрабатывает текстовые и семантические визуальные токены и оптимизируется по задаче next‑token prediction; эксперт генерации LLMGEN работает с VAE‑латентами и обучается по flow‑matching в непрерывном латентном пространстве. Оба эксперта разделяют общую контекстную последовательность, а их потери комбинируются с настраиваемыми весами в процессе обучения, что позволяет гибко балансировать качества понимания и генерации.
Авторы ввели Modality‑Aware Rotary Positional Encoding (MaPE) для различения групп визуальных токенов в единой последовательности: MaPE добавляет фиксированный временной сдвиг каждой модальности, одновременно сохраняя пространственные координаты. В абляциях удаление MaPE ухудшает результаты: GenEval падает с 80.94 до 80.56, GEdit‑Bench — с 6.86 до 6.30; при этом отмечается и снижение показателя VBench (исходное значение 81.8), что подчёркивает роль специализированного позиционирования для согласованной работы мультимодальной последовательности.
Источники
Ответы (0)
Пока нет ответов в этой теме.