1 июня 2026 года на GTC Taipei в рамках COMPUTEX анонсировали Cosmos 3 — открытую world foundation‑модель для физического ИИ, которая объединяет зрительное рассуждение, мультимодальную генерацию и предсказание действий. Модель предназначена для того, чтобы роботы, автономные транспортные средства и визуальные агенты предвидели изменения в сцене и формировали физически обоснованные управляющие сигналы до выполнения действий, что снижает риски и ускоряет цикл обучения и тестирования.
Cosmos 3 построена на архитектуре mixture‑of‑transformers: отдельный блок рассуждения сначала интерпретирует происходящее в сцене, затем блок генерации использует этот контекст для производства выходов, согласованных с физикой среды. Система поддерживает текст, видео, изображения, фоновые звуки и нативную генерацию действий — числовые сигналы вроде углов сочленений, позиций захватов и точек траекторий — и допускает пост‑тренировку политик под конкретную морфологию робота, расположение камер, рабочее пространство и задачу.

Разработчики подчёркивают, что в реальных условиях — на складах, дорогах и заводах — системы должны не только обнаруживать объекты, но и предсказывать их поведение: например, выход пешехода из между припаркованных машин или траекторию вилочного погрузчика. Сбор таких сценариев в физическом мире медленный и дорогой; поэтому Cosmos 3 ориентирована на генерацию реалистичных данных и сцен с физическим контекстом, чтобы ускорить цикл обучения и валидации. Для инженерных команд модель облегчает масштабирование наборов данных и политик: она генерирует пары «наблюдение→действие» для тренировок, синтетическое видео и варианты сцен, что повышает разнообразие траекторий и эффективность симуляций. Дополнительные выходы — плотные подписи, предсказания изменений сцены и сценарные вариации — дают более информативный контекст для операторов и систем мониторинга.

В релизе описаны практические интеграции и примеры использования. Команда NVIDIA GEAR применяет Cosmos 3 для разработки video action models, а Agile Robots использует модель для генерации action‑conditioned данных при обучении гуманоидов и других платформ, включая Thor 3 и FR3. В публикации приведены примерные подсказки для генерации действий, например: «Put all the bananas on the plate» и «Pick the Core Electric Wire and put it in the bin using both arms».
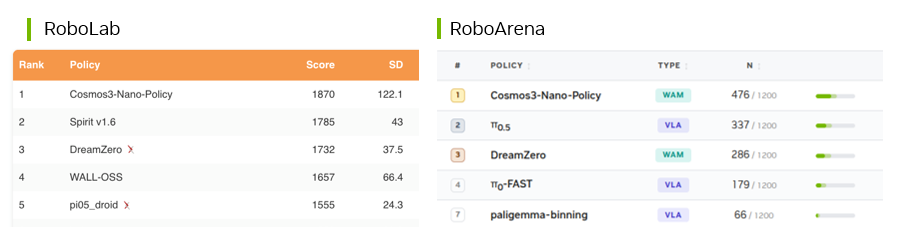
Cosmos 3 Nano-версия с пост‑тренированной политикой — лидирует в тестах RoboLab в симуляции и сравнивается в RoboArena на DROID‑роботах в реальных средах, что демонстрирует применимость модели как в виртуальных, так и в физических тестах. Такие результаты указывают на возможность ускорить переход от симуляции к полевым проверкам. Модель также ориентирована на интеллектуальные города и промышленные пространства: она определяет движущиеся объекты, места пересечения путей и генерирует прогнозы изменений сцены, которые помогают выявлять аномалии и проводить корневой анализ инцидентов. Linker Vision использует возможности vision‑language reasoning и цифровые двойники Cosmos 3 для анализа живых видеопотоков и извлечения пространственного контекста в промышленных и инфраструктурных решениях.
Источники
Ответы (0)
Пока нет ответов в этой теме.