Databricks и Health Samurai 27 мая 2026 опубликовали описание концепции FHIR‑native платформы на Databricks Lakebase, которая стандартизирует входящие клинические, лабораторные, страховые транзакционные и данные о социальных детерминантах здоровья (SDoH) в единый, доверенный «последний миля» для аналитики и операций. Идея в том, чтобы приводить данные к FHIR уже при приёме и хранить их в Lakebase так, чтобы один и тот же набор записей был сразу доступен для массового сканирования, ML‑пайплайнов, AI‑агентов и BI‑дашбордов, устраняя необходимость в постоянных перемещениях и репликации.
Это важно для организаций, которые планируют масштабировать AI‑инициативы и ускорить запуск интеллектуальных приложений. Авторы публикации подчёркивают, что текущая, «традиционная» схема работы со здравоохранительными данными разделяет интероперабельность и аналитику: отдельный FHIR‑сервер для обмена и отдельное аналитическое хранилище, сведённые вместе сетью ETL‑конвейеров. Такое дублирование создаёт лишние затраты на хранение и вычисления и нередко превращает FHIR‑сервер в узкое место — этот компонент изначально оптимизирован под транзакционные сценарии, а не под массовое сканирование и обучение моделей. Результат — замедленное движение данных, фрагментированное управление доступом и аудитом, рост затрат и торможение AI‑проектов.
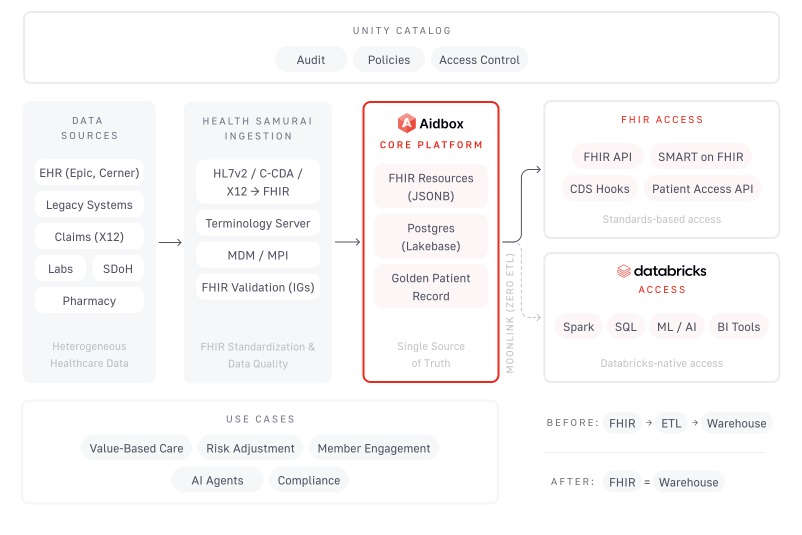
Ключевая архитектурная идея проекта — обрабатывать и нормализовать источники сразу в FHIR‑формат при приёме и сохранять их в Lakebase так, чтобы тот же набор записей обслуживал и оперативные, и аналитические запросы без повторной репликации. В предложенной архитектуре Health Samurai отвечает за слой агрегации и нормализации, который собирает данные из EHR, лабораторий и других систем и конвертирует их к единой FHIR‑структуре перед загрузкой в Lakebase. По замыслу авторов, это упрощает контроль версий данных, доступ и аудит, снижая операционные издержки.
Для разработчиков и интеграторов публикация даёт конкретику по поддерживаемым форматам и семантике: входные форматы и API опираются на HL7 и X12, включая FHIR R4/R5, HL7 v2, C‑CDA и X12; клиническая семантика выражается через LOINC, SNOMED CT, RxNorm и ICD‑10. Соответствие конкретным сценариям задаётся через FHIR Implementation Guides — в тексте упомянуты US Core, CARIN Blue Button, Da Vinci PDex и mCODE — при этом авторы отмечают, что набор IG и кодовых систем может дополняться по мере изменения регуляторных требований и партнёрских интеграций.
Авторы ожидают, что единый FHIR‑набор в Lakebase сократит потребность в репликации данных, упростит соответствие регуляторным требованиям и ускорит внедрение интеллектуальных приложений, которые зависят от чистой, управляемой и единообразной базы. Практические преимущества, по их оценке, включают сокращение затрат на хранение и вычисления, более согласованный аудит доступа и ускорение аналитических и ML‑проектов.
Источники
Ответы (0)
Пока нет ответов в этой теме.