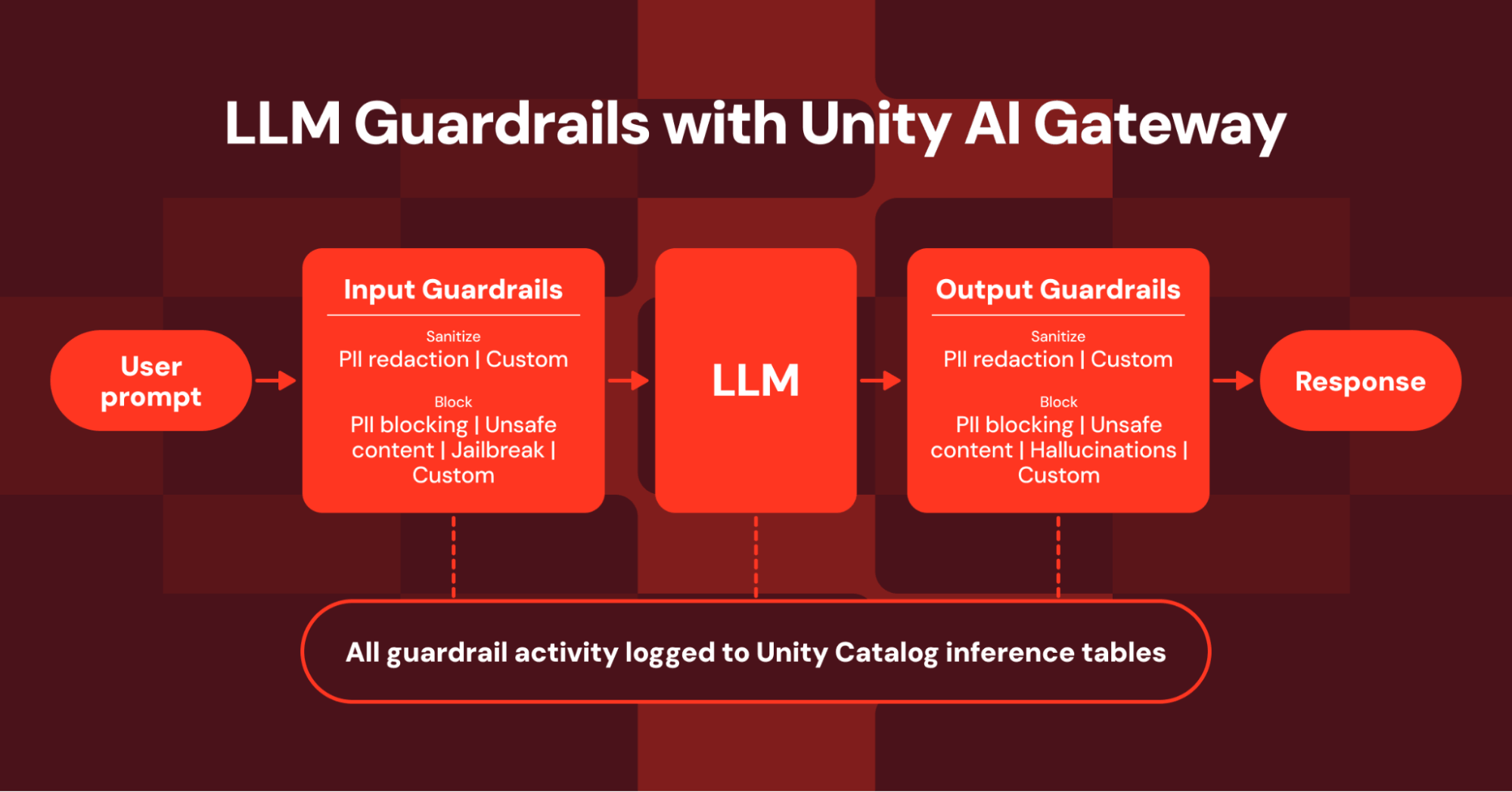
Databricks 19 мая 2026 года представила бета‑версию LLM Guardrails в Unity AI Gateway — набор средств контроля для защиты AI‑нагрузок от утечек личных данных, атак типа jailbreak/prompt injection и генерации опасного контента. Этот релиз важен тем, что объединяет безопасность и комплайенс на уровне вызовов LLM и даёт командам платформ и разработчикам инструменты для централизованного управления рисками. Новая бета‑функция использует LLM‑механизмы для расширения и повышения эффективности встроенных ограждений и добавляет опцию полностью настраиваемых guardrails. Для каждого преднастроенного шаблона предусмотрено предопределённое действие — block или sanitize — и связанная подсказка; при создании ограждения можно выбрать тип, задать конфигурации и переключить режим работы.
В блоге приведён практический сценарий: маркетинговая команда собирает ассистента и сопоставляет бизнес‑правила с готовыми шаблонами. В примере команда сопоставила требования следующим образом: запрет утечки PII — PII Detection & Redaction → Sanitize Input; фильтрация jailbreak/prompt injection → Jailbreak & Prompt Injection → Block Input; блокировка опасного контента — Unsafe Content Blocking → Block Output; запрет на упоминание конкурентов — Custom Block Output. Для управляемого эндпойнта в примере выбрана модель общего назначения GPT‑5.4 и соответствующий endpoint.
Авторы рекомендуют настроить inference tables для мониторинга работы ограждений и проверки их эффективности на реальном трафике. По умолчанию для оценки (evaluator) предлагают лёгкую модель databricks‑gpt‑5‑nano, но этот evaluator можно менять, чтобы сбалансировать производительность и затраты — например, использовать более легкую модель для быстрых проверок и мощную для критичных сценариев. Публикация отсылает к Databricks AI Security Framework, где перечислены 97 отраслевых рисков безопасности ИИ и 73 доступных контрмеры на платформе. Текст подчёркивает, что ограждения служат не только для предотвращения взломов и утечек, но и помогают блокировать вредоносный или оскорбительный контент, поддерживать соответствие бренд‑стратегии и удерживать диалоги в требуемой теме.
Для минимизации риска ошибок на живом трафике авторы советуют при развертывании сначала включать Advanced Mode → Log (режим логирования), а после проверки переходить в Enforce для жёсткого применения политик. Поскольку функциональность находится в бете, командам рекомендовано тестировать настройки, подбирать evaluator с учётом затрат и производительности и постоянно отслеживать метрики через inference tables.
Источники
Ответы (0)
Пока нет ответов в этой теме.