В техническом разборе от 8 мая 2026 авторы утверждают, что поддержка окна в 1 млн токенов в DeepSeek‑V4 становится прежде всего проблемой систем инференса и организации KV‑кеша, а не только модельной архитектуры.
8 мая 2026 в техническом разборе DeepSeek‑V4 утверждается: ключевая перемена — миллион‑токенный контекст уже не просто модельный трюк, а системная задача инференса, поскольку требования к хранению и обслуживанию состояний KV‑кеша выходят на первый план. Это меняет фокус работы инженеров: теперь важны не только архитектурные приёмы уменьшения состояния, но и то, как сервисы хранят, пересчитывают и вытесняют состояния при реальных нагрузках.
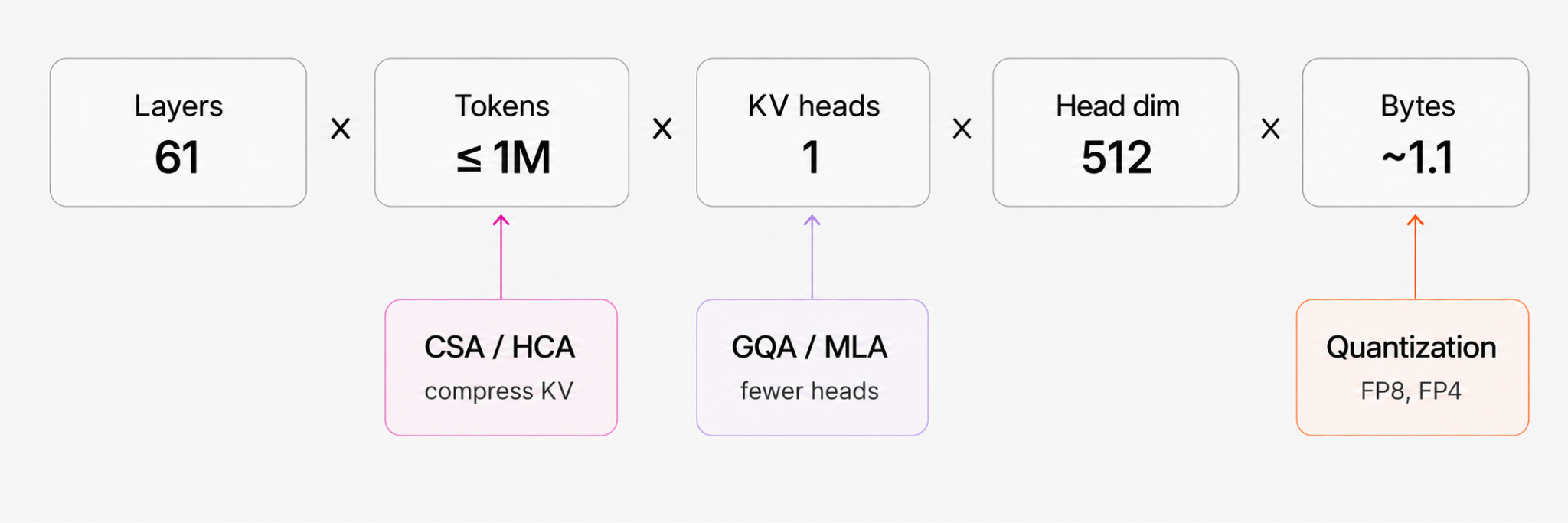
Архитектурное решение V4 опирается на гибридный дизайн внимания — Compressed Sparse Attention (CSA), Heavily Compressed Attention (HCA) и Sliding Window Attention (SWA). Модель сжимает ось токенов перед записью в KV, комбинирует сжатые и локальные пути внимания и перерабатывает логику повторного использования префиксов. В тексте приводят формулу влияния на объём кеша: KV cache ∝ layers × tokens × kv_heads × head_dim × bytes, что подчёркивает многомерный эффект на ёмкость хранения.
Разбор сопоставляет V4 с предыдущими приёмами снижения нагрузки: Group Query Attention (GQA) уменьшает число KV‑гедов, Multi‑Head Latent Attention (MLA) сжимает KV в латентное представление, а низкопрецизионные форматы (FP8, MXFP4, NVFP4) сокращают количество байт на элемент. DeepSeek‑V3.2 снижал число читаемых KV при декоде; V4 же целенаправленно оптимизирует именно ось токенов и уменьшение объёма хранилища контекста.
Практическая проверка на NVIDIA HGX B200 показала, что архитектурное сжатие даёт выигрыш только при соответствующей поддержке со стороны движка инференса: он должен уметь управлять новыми раскладками кеша, восстанавливать локальное состояние, эффективно батчить запросы и подбирать профили эндпоинтов под длинные контексты. На раннем bring‑up полная реализация SWA давала больший per‑token KH‑отпечаток (≈3.8 КБ/токен) по сравнению с путём V3 (≈3.4 КБ/токен), потому что движок сохранял полное состояние sliding‑window.
Реальный практический выигрыш пришёл от более избирательной политики кеширования: оставляя в кеше только SWA‑состояния, которые реально переиспользуются, объём удерживаемых токенов на одном узле HGX B200 вырос примерно с 1.2 млн до 3.7 млн токенов при минимальных изменениях. Это демонстрирует, что архитектурно‑модельные улучшения создают возможность, но фактическая ёмкость и пропускная способность зависят от системных решений по хранению, пересчёту и вытеснению состояний.
Авторы отдельно отмечают, что V4 включает и другие изменения — Manifold‑Constrained Hyper‑Connections (mHC) и выбор оптимизатора Muon-но для инженеров инференса приоритеты иного порядка: зрелость ядер (kernel maturity), оптимальные раскладки KV, продуманное префикс‑кеширование, стратегии батчинга и профили эндпоинтов. По их мнению, таблицы бенчмарков мало помогают без адаптации сервиса под новую организацию состояния.
Источники
Ответы (0)
Пока нет ответов в этой теме.