Hexo Labs выложила под лицензией MIT SIA-фреймворк для циклического самосовершенствования агентов, который по ходу итераций может либо переписать «каркас» агента, либо обновить веса модели (через LoRA).
Hexo Labs открыла SIA (Self‑Improving AI) под MIT: это набор компонентов для организации петли самосовершенствования агента, где итерации меняют либо инфраструктуру агента (scaffold/harness), либо сами веса модели. Такая схема позволяет не ограничиваться фиксированным каркасом или неизменной моделью и даёт путь к одновременному улучшению логики диспетчеризации инструментов и параметров сети. Архитектура делит агента на harness (скелет) и веса модели. Три LLM‑компонента управляют петлёй: Meta‑Agent генерирует стартовый scaffold, Task‑Specific Agent выполняет задачу и логирует траекторию, а Feedback‑Agent читает лог и решает следующее действие — переписывать scaffold или запускать обучение весов, причём он также выбирает алгоритм обучения в зависимости от формы награды.
В реализации базовой моделью служит openai/gpt-oss-120b; обновления весов делают через LoRA с рангом 32. Meta‑ и Feedback‑агенты работали на Claude Sonnet 4.6, а обучение выполнялось на H100 с помощью Modal. Исходный код доступен как пакет sia‑agent с четырьмя тестовыми задачами и демонстрацией двух рабочих точек: SIA‑H (только harness) и SIA‑W+H (harness + обновления весов).
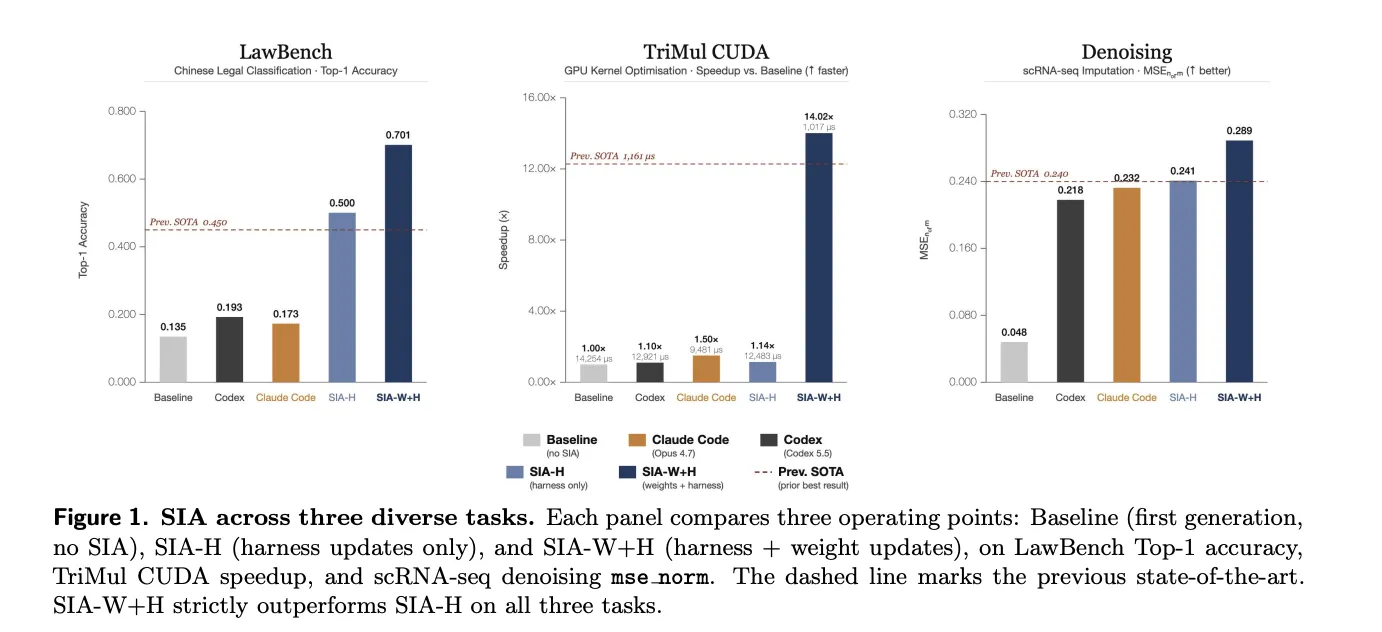
Авторы сравнили два режима: SIA‑H и SIA‑W+H. На трёх доменах комбинированный режим показал заметное улучшение по сравнению с итерациями только каркаса. Для LawBench (191 класс, top‑1) результаты прошли путь: initial 13.5%, прошлый SOTA 45.0%, SIA‑H 50.0% и SIA‑W+H 70.1%. Для TriMul (CUDA‑ядро для AlphaEvolve) reward: 0.105 → 1.292 → 0.120 → 1.475 (соответственно initial → prev SOTA → SIA‑H → SIA‑W+H). Для задачи denoising (scRNA) mse_norm последовательно: 0.048 → 0.240 → 0.241 → 0.289.
Практические кейсы иллюстрируют, как это работает: на LawBench итерации harness выстроили TF‑IDF + LinearSVC и застряли на 50.0%, а последующий LoRA‑апдейт через PPO поднял точность до 70.1% (+20.1 п.п.). Для TriMul обновление весов сократило время выполнения CUDA‑ядра с 12 483 до 1 017 мкс (≈91.9% уменьшение). Для denoising одно двухстрочное изменение в чекпойнте — округление значений в импутах — увеличило mse_norm до 0.289.
Ключевая роль Feedback‑Agent: после каждой траектории он выбирает между переписыванием scaffold и запуском обучения весов, а также подбирает алгоритм. В экспериментах LawBench использовал PPO с GAE, TriMul — entropic advantage weighting (чтобы апдейтить редкие высокие вознаграждения при множественных неудачах компиляции), denoising — GRPO. Авторы также тестировали REINFORCE с KL к базовой модели, DPO и best‑of‑N поведенческое клонирование. Авторы предупреждают о лимитах: результаты приведены по трём доменам, а выбор алгоритма обучения адаптируется к форме награды, что усложняет прямую обобщаемость на другие задачи. Для инженеров это означает необходимость оркестрации нескольких моделей (Meta/Feedback на Claude Sonnet 4.6 и базовая модель для LoRA) и заметные вычислительные ресурсы — в экспериментах использовались H100.
Источники
Ответы (0)
Пока нет ответов в этой теме.