JetBrains выпустила открытые веса семейства Mellum2-12‑миллиардной модели с архитектурой Mixture‑of‑Experts (MoE). Публичный релиз включает шесть контрольных точек под лицензией Apache 2.0 и рассчитан на интеграцию Mellum2 как «фокальной» быстрой компоненты в мульти‑модельные пайплайны для инженерии ПО: генерации и отладки кода, многошагового рассуждения и вызова инструментов. Набор публикаций охватывает этапы до и после удлинения контекста, а также версии с супервизионной донастройкой и RL‑тюнингом. В комплект вошли контрольные точки, отражающие ключевые стадии пайплайна: Base‑Pretrain (до удлинения контекста), Base (после удлинения), Instruct‑SFT (супервизионная SFT), Thinking‑SFT (SFT с трассой рассуждений), Instruct RL‑tuned и Thinking RL‑tuned (RLVR). Лицензия и набор чекпоинтов упрощают интеграцию, донастройку и экспериментирование в рабочих процессах.
Архитектура Mellum2 — классическая MoE: суммарно 12 млрд параметров при активной эквивалентной нагрузке на токен примерно 2.5B dense. Модель содержит 64 эксперта и активирует 8 экспертов на токен, имеет 28 слоёв и скрытый размер 2304. В реализации используется Grouped‑Query Attention (32 query‑хеда, 4 KV‑хеда), Sliding Window Attention с окном 1024 на трёх из четырёх слоёв и один слой с полной внимательностью. Дополнительно указаны Multi‑Token Prediction head, точность bfloat16 и словарь в 98 304 токена; мультимодальности (изображения/видео) не поддерживаются.
Предобучение охватило примерно 10.6 трлн токенов и проходило в три фазы с постепенным смещением смеси данных от широкого веб‑контента к курированному коду и математике. Для оптимизации использовали Muon optimizer при гибридной FP8‑точности, со схемой Warmup‑Hold‑Decay и линейным затуханием скорости обучения до нуля. Базовую модель перед пост‑тренингом увеличили до окна 128K токенов с помощью layer‑selective YaRN; в описании архитектуры указан финальный контекст 131072 токена. Пост‑тренинг включал SFT, после чего применялся RL с верифицируемыми наградами (RLVR) для задач математики, исполняемого кода, использования инструментов, следования инструкциям и рассуждений. Такой пайплайн дал две линейки — Instruct для быстрых инструкций и инструментального использования и Thinking для задач с трассой рассуждений и отладки.
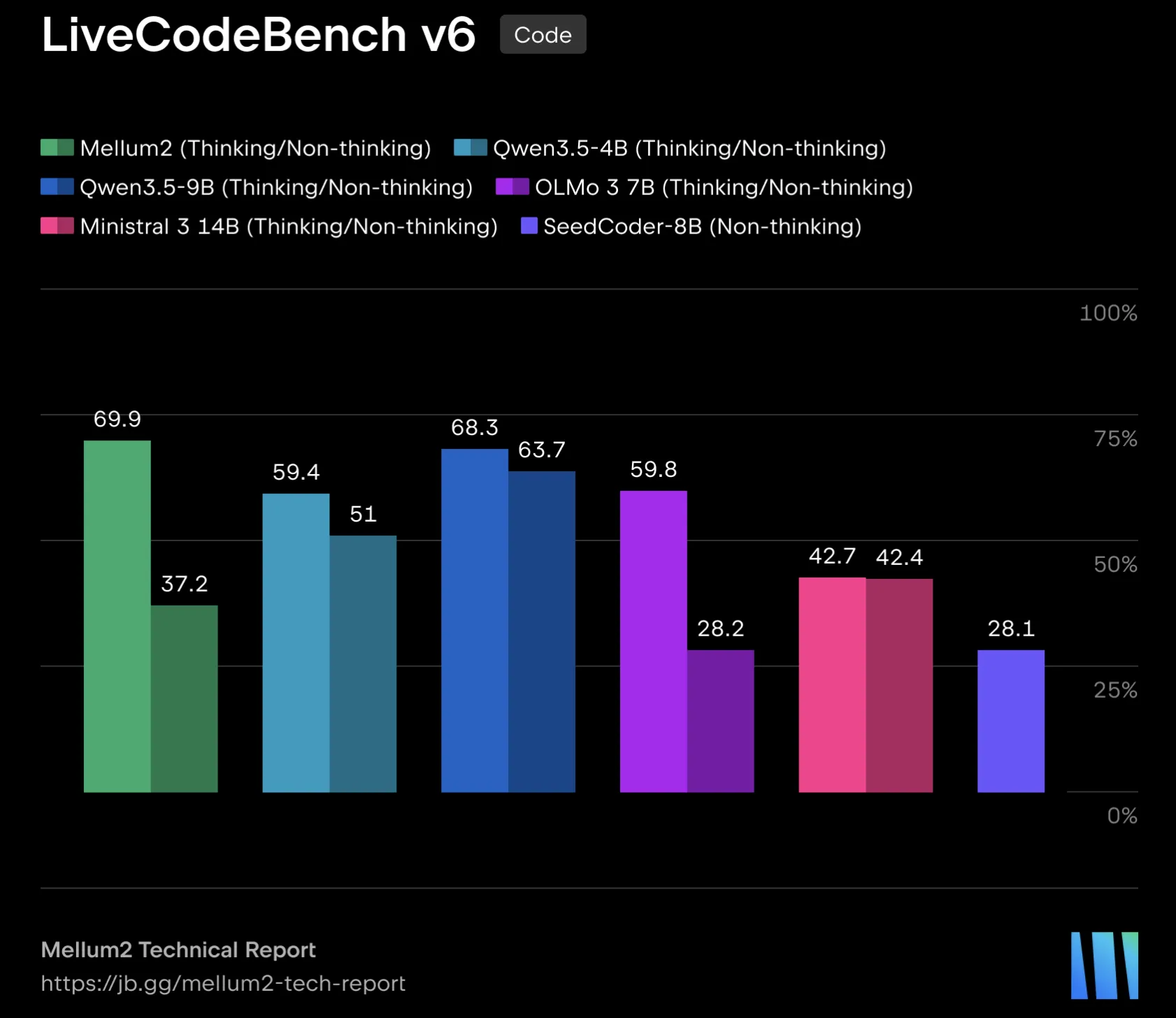
JetBrains привела сравнительные результаты по ряду бенчмарков для открытых моделей в диапазоне 4B-14B (все значения self‑reported). Примеры: LiveCodeBench v6-Mellum2 Instruct 37.2 (Qwen3.5 4B-51.0, Ministral3 14B-63.7); EvalPlus — Mellum2 78.4 (Qwen3.5 4B-69.4); AIME 2025+2026 — 41.7 (Qwen3.5 4B-38.3, Ministral3-58.3); MMLU‑Redux — 78.1. Эти метрики дают ориентир по месту Mellum2 среди открытых моделей схожего масштаба.
Практическое значение в том, что MoE‑архитектура предоставляет высокую параметрическую ёмкость при относительно низких пер‑токен расчётах, что делает Mellum2 подходящим для ролей с требованием низкой задержки внутри сложных пайплайнов: Instruct‑вариант — для быстрых подсказок и вызова инструментов, а Thinking‑вариант — для сложной отладки и многошаговой логики. Наличие шести чекпоинтов и лицензии Apache 2.0 снижает барьеры для интеграции, донастройки и исследований в продуктивных сценариях.
Источники
Ответы (0)
Пока нет ответов в этой теме.