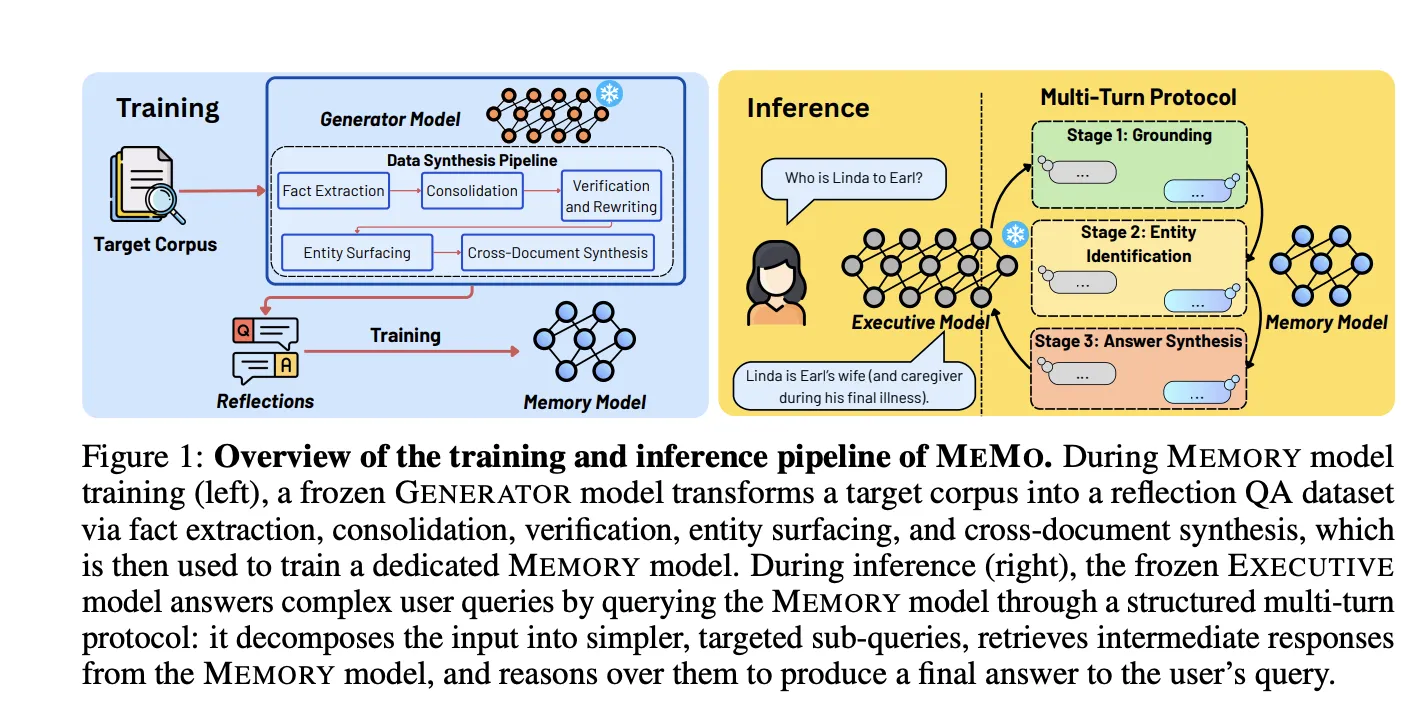
Исследователи предложили MEMO-модульную архитектуру, в которой корпусные знания кодируются в отдельной обучаемой модели памяти, позволяющей обновлять факты в закрытых или «замороженных» LLM без доступа к их весам.
Команда из NUS, MIT CSAIL, A*STAR и SMART представила MEMO-подход, который позволяет обновлять знания больших языковых моделей через отдельную обучаемую модель памяти, не трогая параметры «исполнительной» модели. Это важно для случаев с проприетарными или слишком тяжёлыми для переобучения LLM: разработчики могут вносить новые факты и улучшать междокументное рассуждение без дорогостоящего полного дообучения или доступа к весам EXECUTIVE.
Ключевая идея — разделение ролей: отдельно обучаемая MEMORY хранит и интернализирует корпусные факты, а основной EXECUTIVE остаётся «замороженным» и общается с ней через стандартный ввод‑вывод. В экспериментах MEMORY использовали Qwen2.5‑14B‑Instruct, а EXECUTIVE представляли Qwen2.5‑32B‑Instruct и закрытая Gemini‑3‑Flash. Подход не требует доступа к весам EXECUTIVE или к его логитам, что делает его совместимым с закрытыми моделями.
Обучение MEMORY начинается с пятиступенчатого пайплайна синтеза данных, управляемого GENERATOR‑моделью (в экспериментах — Qwen2.5‑32B‑Instruct). Последовательность включает: извлечение прямых и косвенных фактов; консолидацию QA‑пар с общим контекстом; верификацию и перезапись для получения самодостаточных пар; «выведение» сущностей через вопросы‑ответы; и сквозной синтез по нескольким документам. Авторы подчёркивают значение последнего этапа: при его исключении точность на наборе NarrativeQA упала с 24.00% до 6.37%.
После синтеза MEMORY дообучается в режиме supervised fine‑tuning с вычислением функции потерь только по токенам ответа; при инференсе исходные документы не подаются, то есть модель должна отвечать из внутренней параметрической памяти. Такой режим отличает MEMO от RAG, где ответы зависят от извлечённой внешней базы, и от латентных методов, которые создают представления, тесно связанные с конкретной моделью‑создателем.
Для взаимодействия EXECUTIVE и MEMORY авторы предложили структурированный мульти‑туровый протокол из трёх последовательных стадий. Описанные первые две стадии — Grounding (декомпозиция запроса на атомарные подвопросы, каждый с одним идентифицирующим ограничением) и Entity identification (по ответам EXECUTIVE итеративно сужает круг кандидатов через целевые уточняющие запросы). Такой протокол делает MEMO пригодным для работы с закрытыми или «замороженными» моделями без модификации их весов. Авторы позиционируют MEMO как компромисс между непараметрическими методами, чувствительными к шуму в извлечении, и прямым дообучением, которое дорого и склонно к забыванию. Для практики это означает возможность обновлять знания и улучшать междокументное рассуждение, сохраняя совместимость с проприетарными LLM и избегая доступа к внутренним параметрам EXECUTIVE и логитам.
Источники
Ответы (0)
Пока нет ответов в этой теме.