Liquid AI представила LFM2.5-8B-A1B — разрежённую Mixture‑of‑Experts модель для on‑device деплоя: итоговый объём 8,3 млрд параметров, при каждом проходе активируется ≈1,5 млрд, заявлен контекст до 131 072 токенов.
Liquid AI выпустила LFM2.5-8B-A1B, разрежённую (sparse) Mixture‑of‑Experts модель для on‑device использования: общий объём — 8,3 млрд параметров, при генерации активируется примерно 1,5 млрд параметров, что снижает вычислительную стоимость и делает модель применимой на потребительском железе. Это важно для приложений с длинными контекстами и вызовом инструментов, где высокая вычислительная эффективность критична.
Архитектура модели включает 24 слоя: 18 блоков с двойной gated LIV‑сверткой и 6 слоёв GQA, сочетая MoE, GQA и gated short convolution‑блоки. В отличие от предшественника, LFM2.5-8B-A1B рассчитана на генерацию рассуждений и по умолчанию выдаёт явную цепочку мыслей перед финальным ответом; для практического использования разработчики рекомендуют параметры выборки temperature=0.2, top_k=80 и repetition_penalty=1.05.
По контекстной длине и токенизации заявлено до 131 072 токенов; команда отмечает, что по сравнению с LFM2‑8B‑A1B окно контекста было расширено с 32 768 до 128 000 токенов. Масштаб предобучения вырос с 12T до 38T токенов, словарь — с 65 536 до 128 000 токенов для улучшенной токенизации нелатинских языков; модель покрывает девять языков, включая арабский, китайский и японский. Авторы указывают на наибольшую выгоду по сжатию для хинди, тайского, вьетнамского, индонезийского и арабского; при этом остальная часть архитектуры осталась в основе прежней. Процесс обучения включал «in place» расширение токенайзера (продолжение BPE‑merge на многоязычном корпусе) и инициализацию новых эмбеддингов как среднего по субтокенам с двухэтапной адаптацией качества.
Увеличение контекста проводилось поэтапно: первоначальный 2T‑этап довёл модель до 32K с фокусом на рассуждения и использование инструментов, затем подняли RoPE‑базу θ и провели этап на 400B токенов до 128K. Две RL‑фазы (preference optimization и avg@k‑shaping) были направлены на снижение «петель» в длинных рассуждениях, уменьшение перезапусков слов и сокращение галлюцинаций с акцентом на воздержание при ненадёжных запросах.
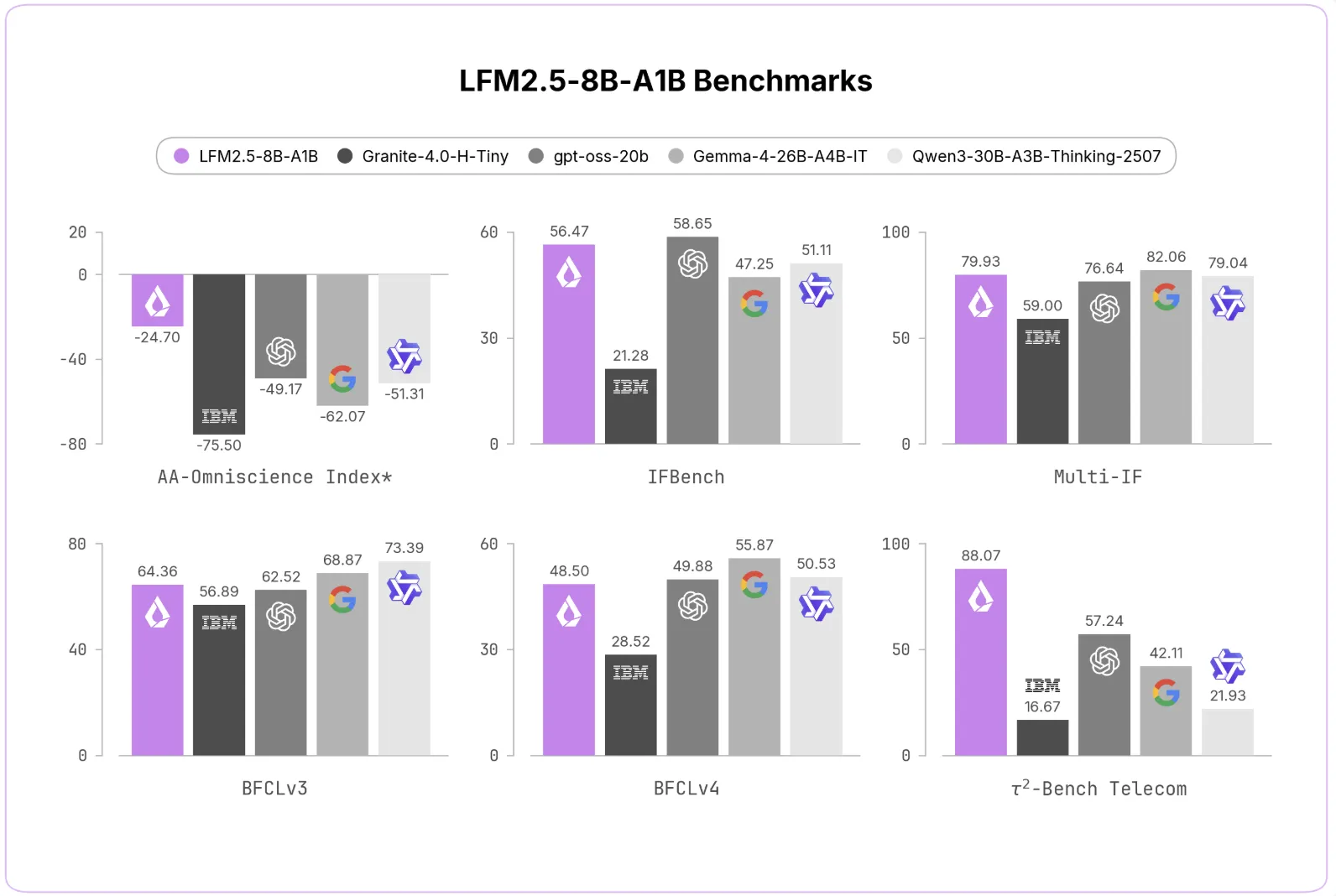
В бенчмарках LFM2.5-8B-A1B демонстрирует существенные улучшения: AA‑Omniscience Non‑Hallucination Rate вырос с 7.46 до 63.47, IFEval — с 79.44 до 91.84, MATH500 — с 74.80 до 88.76, Tau² Telecom — с 13.60 до 88.07. Команда отмечает, что на задачах инструкций модель сопоставима с Gemma‑4‑26B‑A4B‑IT по IFEval при значительно меньшем числе активных параметров и превосходит многие более крупные модели по ряду телеком‑метрик.
Модель доступна с дня релиза в экосистеме inference: поддержка llama.cpp, MLX, vLLM, SGLang, ONNX и собственной LEAP edge‑платформы. По измерениям производительность составляет: на CPU M5 Max — ≈253 токена/с, на Ryzen AI Max+ 395 — ≈146 токена/с, потребление памяти остаётся ниже 6 ГБ; на телефоне — около 30 токенов/с. На одной NVIDIA H100 SXM5 заявлен пик ≈18 500 токенов/с (что при высокой конкуренции даёт более 1,6 млрд токенов в сутки). Для интеграции инструментов модель по умолчанию генерирует «pythonic» вызовы функций.
Источники
Ответы (0)
Пока нет ответов в этой теме.