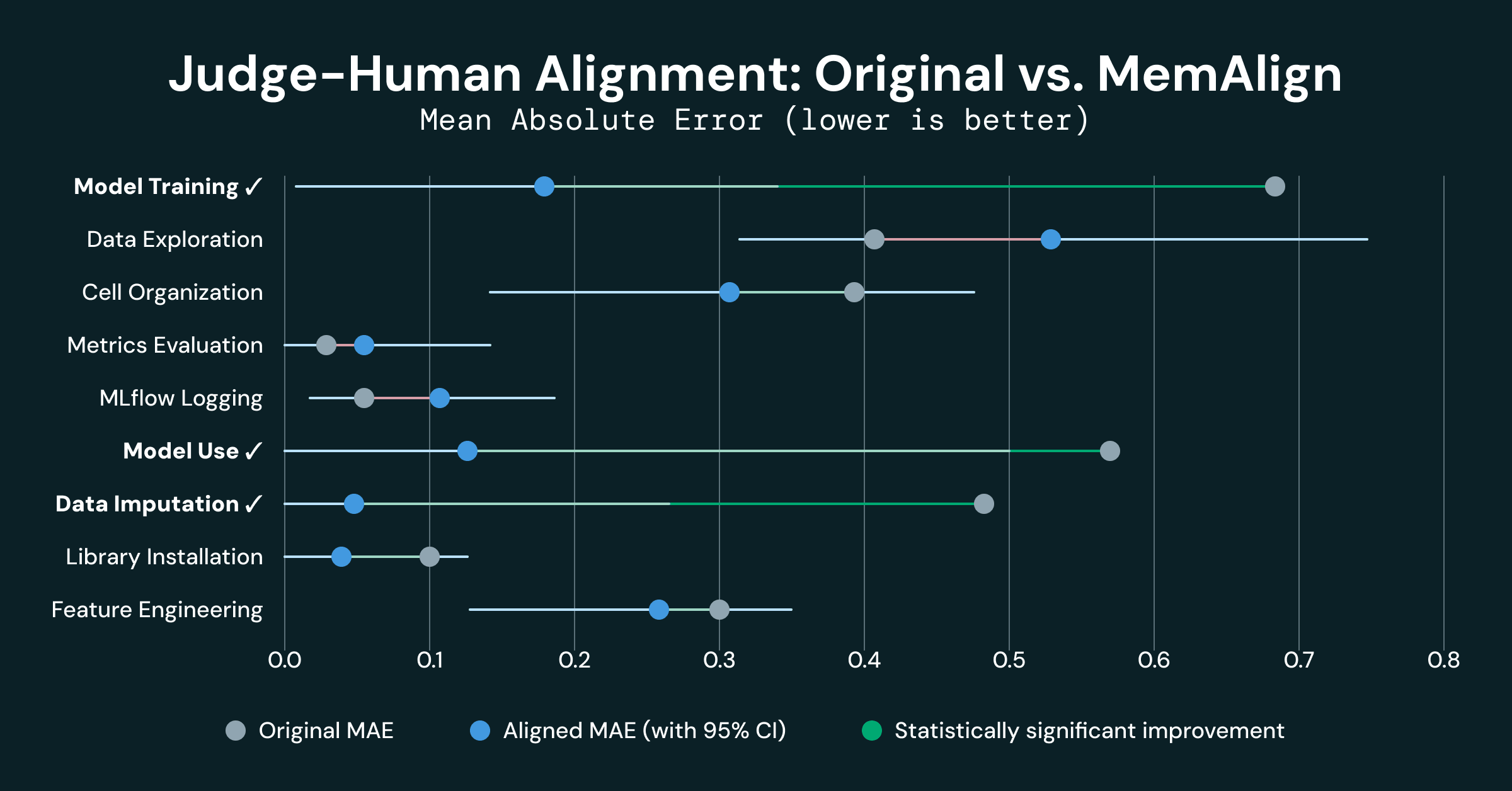
Команда разработчиков применила MemAlign — открытый фреймворк выравнивания в MLflow — чтобы улучшить автоматическую проверку ноутбуков, генерируемых Genie Code, и сократить «масштабный разрыв» между суждениями LLM‑судей и оценками людей‑экспертов. Это важно: согласованная автоматическая оценка позволяет быстрее находить регрессии и количественно измерять эффект изменений в промптах, моделях и архитектуре агентов. Genie Code представлен как автономный AI‑партнёр для работы с данными, интегрирующий несколько агентов и новые точки интеграции. Ключевой технический фактор — глубокая интеграция с Unity Catalog: система опирается на метаданные таблиц, столбцов, lineage, views с метриками и бизнес‑определениями, что повышает контекстную осведомлённость при генерации рабочих процессов и снижает риск ошибок, связанных с неверной семантикой данных.
Ожидаемый исход генерации ноутбука для задачи наподобие прогноза оттока — production‑готовый ML‑workflow: установка зависимостей Python, разведочный анализ данных (EDA), препроцессинг и импутация, обучение и тюнинг модели, регистрация и деплоймент, а также оценка производительности. Система должна автоматически адаптироваться к особенностям данных — например, учитывать несбалансированные классы и подбирать соответствующие метрики и процедуры валидации. Для системной оценки авторы построили комплексный evaluation‑пайплайн, где LLM‑виды судей работают совместно с MemAlign. Фреймворк применяют для hillclimbing (оценки влияния изменений промптов, инструментов и архитектуры), защиты от регрессий между этапами, бенчмаркинга разных фаундейшн‑моделей и интеграции в CI‑процессы, чтобы изменения в агентном цикле можно было проследить до финальных ML‑задач.
В эксперименте использовали девять LLM‑судей, каждый из которых проверяет отдельную размерность качества ноутбука: установка библиотек; разведочный анализ; импутация и обработка пропусков без утечки; feature engineering; отбор и трансформации признаков; обучение и кросс‑валидация; логика инференса; выбор метрик и логирование в MLflow; организация кода и читаемость ячеек. 3 (Good) — соответствует лучшим практикам и учтённым краевым случаям, 2 (Average) — базовый уровень с недочётами, 1 (Bad) и 0 (неприменимо).
Унификация рубрик совместно с MemAlign повысила согласованность автоматических и человеческих оценок, что позволило автоматизированным судьям выявлять и исправлять конкретные ошибки генерации: отсутствие кросс‑валидации, незамеченные утечки данных, некорректную импутацию и другие нарушения практик. Кроме того, подход дал инструмент для количественной оценки того, как изменения в промптах, моделях и архитектуре агента влияют на итоговое качество ML‑workflow.
Источники
Ответы (0)
Пока нет ответов в этой теме.